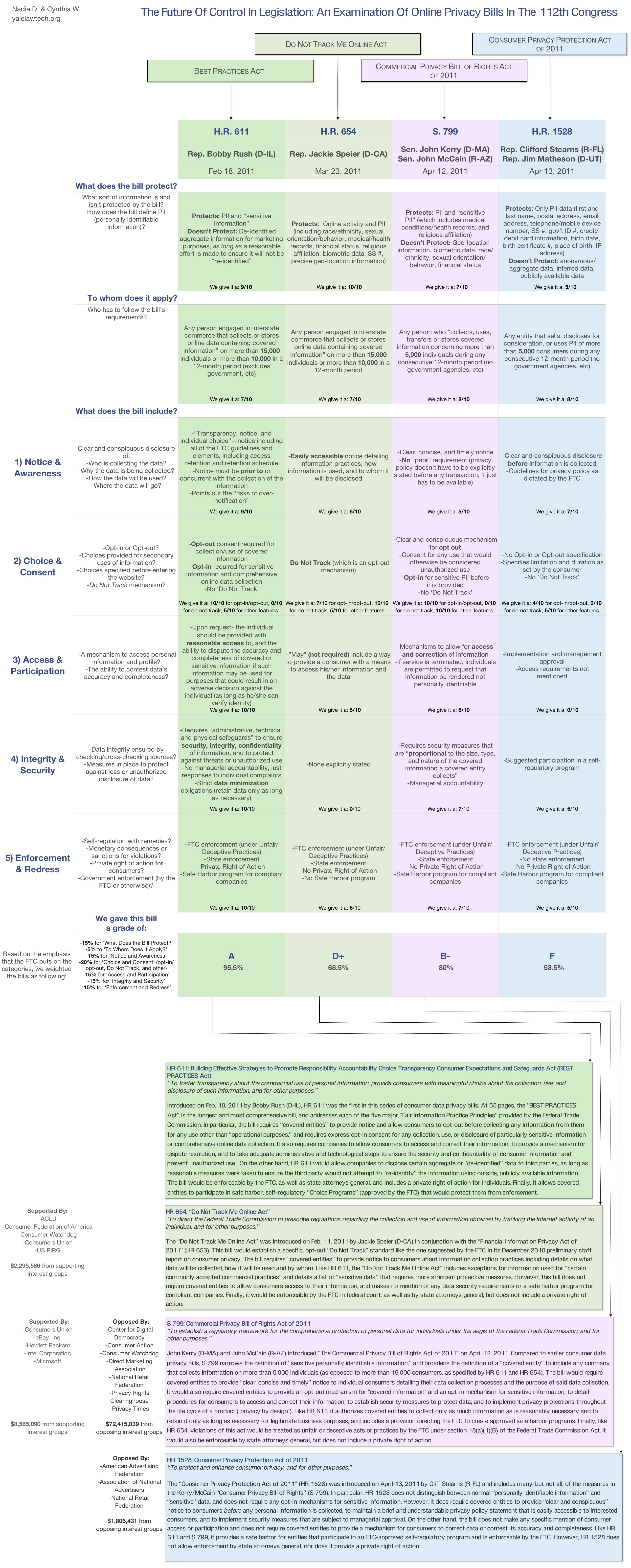
Facebook’s a monopoly that abuses its users: you and me. But we’re left without a way to retaliate. I propose a way to contaminate their database with false information, limiting the usefulness and resale value of our own information, while maintaining as much Facebook usefulness for the rest of us. It’s called Unsell Yourself, and I’d be honored if you’d give it a read.
[Edit: Reposted from my own blog in full, but formatting/CSS is better on my blog]
This is the story of how Facebook uses the information you put into it against you, and how you can unsell yourself. I believe Facebook is an exciting product and I hope that the company succeeds. But I also think Facebook’s monopoly has permitted them a business model which is bad for its users.

Not all stories of businesses harming their consumers begin with a man in a top hat, but it sure makes it easier to. Is Facebook a monopoly? Here’s a graph of Facebook’s web market share compared to hi5, friendster, orkut, linkedin, plaxo, & ning as assembled by Bill Tancer in 2007.

Since 2007, network effects have pushed Facebook into an even more dominant position. Facebook now claims that they have
More than 500 million active users
50% of our active users log on to Facebook in any given day
Average user has 130 friends
People spend over 700 billion minutes per month on Facebook
Alexa.com names Facebook the #2 top site in the world, with 42% of the world’s entire Internet population having visited Facebook. The next social network doesn’t come up until #17: LinkedIn, with a meager 4% of the world’s Internet population.

Here at Yale, in a recent poll of people connected with the class Control, Privacy and Technology (tech savvy 18–22 yr olds, generally), 98.9% of the respondents had a Facebook.
Obvious truth number one: Facebook is the most dominant social network. Facebook alone is in exclusive possession of 500 million people’s communications, demographic data, location, and social habits. Since I’m not even close to being familiar with the nuance of antitrust law, I’ll leave that speculation to other people, noting only that Wikipedia says that the Sherman Antitrust Act doesn’t forbid innocent monopolies, but only those who achieve their monopoly through misconduct.
How Facebook’s Monopoly Harms Users
You might be asking (reasonably), “So what, who cares?” that Facebook is a monopoly. But Facebook’s definitely not been perfect, and their monopoly has permitted them some egregious abuses of their users that a competitive environment would not have permitted. As many Internet-based businesses know, it’s very very dangerous to abuse your users: they’re fickle, and can change services easily by merely navigating to their browser bar. Just look at Digg versus Reddit. So why hasn’t Facebook suffered user base drops when they rolled-out despised changes, like a redesign (the irony of linking Gawker isn’t missed), less default privacy, or ever more tailored behavioral ads. (Full disclosure: I recently got a Facebook behavioral ad for “bedwetting”. Not really sure what I’m doing to signal that one.)
Recently, even spookier things have surfaced. Julian Assange noted that Facebook is an FBI agent’s wet dream:
Facebook in particular is the most appalling spying machine that has ever been invented. Here we have the worlds most comprehensive database about people, their relationships, their names, their addresses, their locations, their communications with each other, their relatives… all accessible to US Intelligence… [Yahoo, Google and Facebook] have built in interfaces for US Intelligence. It’s not a matter of serving a subpoena.
Facebook users should get a Miranda warning:

And Mark Zuckerberg likes looking at more than merely the data you post. By reading between the lines, he’s worked out an algorithm with 33% success rate for predicting who you’ll date next.
Why Users Don’t Quit
I don’t quit Facebook because Facebook is a valuable network, one that can’t be easily replaced. That’s the natural strength of a monopoly combined with Metcalfe’s network benefits, the nature of walled garden web platforms, and their inability to control and remove their own data from Facebook. Walled garden web platforms like Facebook with embedded APIs and developers, along with Facebook-specific applications mean that users can’t easily replace or extract what could be valuable data to them. In other words, quitting Facebook means quitting Farmville and all the other applications you use. As more and more websites use Facebook as the only login system (for the best example, see Canv.as), the web platform expands its power. These kinds of platforms also lead to a new, special kind of hurt of users: the AOL effect. Users’ lack of control over their Facebook data also makes it impossible to quit the platform. Not only is it truly impossible to delete messages (the delete button merely obscures them from user view, but enables them to be re-discovered via Facebook’s “Download Profile” tool and of course they remain on Facebook’s servers for subpoena or hackers and Facebook themselves, but it’s also impossible to pull Facebook contact information out of the roach motel. Even Google has lashed out against Facebook, criticizing Facebook’s design choice that makes users’ unable to export their data back out.
How Users Can Strike Back
Not a single user pays to use Facebook, and yet the company is valued at $50 billion dollars. Not bad: that means that of their users is worth $100, by my math! Which is to say that investors believe that your information, your time on the site, and your clicking is worth $100 to Facebook. To encourage a more competitive marketplace and discourage Facebook from abusing its users, there’s an easy way to reduce your value to Facebook while simultaneously reducing your legal vulnerability and privacy problems, without quitting Facebook, or even losing a valuable component of Facebook’s services!.

You keep all of your Facebook contacts, the ability to message or chat or use your wall and apps— but behavioral advertising, Facebook’s bread and butter dollar revenues and the short term thing that keeps them Wall Street’s darling— you can kill all of that just by adding a “Teen Vogue” to your interests. Or Teletubbies. Or Tiffany’s.
Here’s my current profile:

The trick is to populate your Facebook with just enough lies as to destroy the value and compromise Facebook’s ability to sell you. Collectively, users could use misinformation with “features” that they don’t like being used against them in order to guide Facebook’s future. (This is already done by FB’s user base with new some new features: Facebook places seems to effectively have been a flop. Among my 1000+ Facebook friends, only one person uses it.)
How Google is Different from Facebook
I’m wary of Google, but for now will say it’s not worth populating their data with false information yet, and not just because it’s harder. This stems from three major differences between Facebook and Google:
1. Long term monetization strategy
2. Competitors
3. Data Freedom
I don’t see Google’s long term monetization strategy being pimping your data out to the highest advertising bidder. That might be how you build a $50 billion dollar company, but it’s not a way to build a lasting $200 billion dollar company. Instead, I think they’re collecting data to get into a product development business via big data and simple algorithms.
Nor is Google’s monopoly even close to as complete as Facebook’s dominance. Bing apparently now has 29% of the search market, and Baidu won’t let up the Chinese market easily. There are innumerable competitors to Gmail, and they all have heavy user bases. Online documents is an area Microsoft won’t cede easily, since it’s one of their core products and one of their two sources of profit (Office). Mobile phones are obviously an extremely competitive arena, with RIM, Apple, Microsoft, and HP all fighting for OS market share in smartphones. And even in Google’s stronghold of display ads, Apple’s attacking (though the success of iAds remains to be seen).
Perhaps most important is that Google’s exportability of your data remains high. You aren’t locked in or integrated in the same way that Facebook joins all of your data to a persistent single identity, users can download calendars and quit Google Calendar or extract contacts onto a new framework. The integration also doesn’t lock users into Google: you can continue to use Google Docs even if you discontinue Gmail use.
Conclusion
Ultimately, I see inputting false data into Facebook’s “likes” pages a form of sit-in, a kind of CAPTCHA to prevent a Facebook data mining bot to freely pillage and extrapolate results from the data you put in to Facebook. It’s a good response in a scenario like today, where Facebook has a monopoly that almost everyone has to jump in on anyway, no matter how much they might be reluctant to. Hopefully though, the longer term solution is for a real competitor to emerge, offering users the things that they want, and the ability to migrate effortlessly from Facebook without paying Metcalfe’s prices. In the meantime, protect yourself and express a bit of discontent: unsell yourself from Facebook.