[I]t became clear to me that the one change in the law that will solve the most problems in the simplest way is reform of statutory damages…
Here’s the current scheme in a nutshell. The Copyright Act has two ways that plaintiffs can recover damages in a case of infringement. The first way is the way plaintiffs recover in almost every other civil case: a copyright holder can recover his actual damages and lost profits. But there is also a unique second measure of damages that plaintiffs can recover instead: something called “statutory damages” that can range from $750 to $150,000 per work infringed, constrained only by what a judge or jury “considers just.” There are currently several major fights about just how far such damages can go, like whether you can recover over $600,000 against a regular filesharer who earned no profits and caused no measurable harm, or whether you can recover damages that run into the trillions against the operator of LimeWire. But even if there are some limits in the most extreme cases, the threat of astronomical damages, even when a copyright holder has not shown that infringement has caused him any harm at all, is a very scary prospect.
Last week, Professor Stark asked us to share our thoughts on the single thing we’d most like to see fixed in intellectual property— and I don’t think any of us suggested this one. It seems pretty reasonable from an infringer’s point of view (read Jason’s full post to see the list of problems it solves), but pretty unfavorable to a license holder. It places a heavy burden on the license holder to go out and actually sue everyone to recoup lost profits— statutory damages both discourage infringement with a heavier penalty and provide more money to the license holder even if he or she can’t catch every infringement.
Microsoft and Barnes & Noble are dueling it out over B&Ns Nook reader which runs on Android OS. Microsoft alleges that the Nook infringes on multiple MS patents for things ranging from “tabbing through content” to “document interaction and web surfing”. Microsoft expert Mary-Jo Foley asserts that this is a part of a larger strategy to combat Googles rising market share in the OS market. MS essentially attempted to extort exorbitant royalties from BN for the various infringing features or else face massive lawsuits.
Mike Ros at Buisness Insider points out “Android includes Linux at its core, and Microsoft established years ago that it thinks Linux infringes its patents. (That claim never been tested in court, but tons of Linux distributors have signed licensing deals anyway — which boosts Microsoft’s future claims.) Last year Microsoft began trying to strike deals with Android smartphone makers. HTC signed a deal. Motorola didn’t, and Microsoft sued.” In effect allowing MS to profit from Android’s success.
Is this a misuse of Patent Law? Are they getting a bad rap and in fact they did innovate these features and deserve to be rightfully compensated (ie create an alternate revenue stream)? Or is Microsoft evolving to the next stage in it’s trajectory toward being the panultimate, anti-competitive patent troll?
It has been suggested that the recent House approval of the American Invents bill will generate jobs, and patent reform is a crucial part of economic recovery. The money collected by the Patent Office will be retained by the organization and allow them to expand and more quickly process patent applications. In a way this aspect of the reform does very little to address the bloody tech-giant patent wars, and in fact adopts a similar strategy to microsoft. The alternate revenue stream: Funds generated via the problematic infrastructure of our current patent system.
Congress is currently on the verge of passing its most comprehensive patent reform in decades. The America Invents Act would overhaul much of the organization of the US patent system by creating a patent-specific Trial and Appeals board among other reforms. This is the back end of patent reform. Congress is seeking to adjust the principles on which the USPTO bases its practices in order to overhaul the system. While I do think the proper way of solving the problems with the Patent system is from the inside out, I personally think that the America Invents Act falls short of what needs to be done. But the back-end reform is not all that’s going on.
A front-end adjustment is also in the works. Until the cuts made in staving off a government shut-down this year, the USPTO had been expecting a sizeable increase in funding which would be used to help streamline its operations with new offices, increased personnel, and other practical reform efforts. Indeed, one major provision of the America Invents Act was to give the USPTO full autonomy over the fees it brought in, rather than divert some of it elsewhere in the budget. The $2.3 billion that the patent office was expecting, however, was cut to $2.09 billion, funds remain diverted, and many of the front-end reforms have been forced on hold. At once, Congress has sought to enact and limit patent reform. And the consequences of that limitation could be disastrous. Not only are developments like an expedited application process or a midwest satellite office held indefinitely, but hiring is frozen, overtime is eliminated, and employee training is reduced. This budget doesn’t just place an obstacle before progress in patents, it forces us to regress.
To me, this indicates an ignorance on the part of Congress of the problems of patent law. This contradictory approach to the patent system would not occur if Congressmen understood the scope of what needs to be adjusted, on both the front end and the back end.
The conclusion of a suit filed against Google in 2009 by Bedrock Computer Technologies(a company accused of being a patent troll) has been decided. The jury decided that Google’s use of the Linux kernel in its servers was infringing on a Linux patent. The court ruled that Google should pay 5 million dollars for the infingment.
This ruling is interesting because Linux is widely used in the open source community and the finding of infringement has implications for other users of open source software. The ruling could hurt Google in other patent lawsuits regarding Android software, which also makes use of the Linux kernel. Bedrock also has pending cases against Yahoo, Paypal, Myspace, Amazon and other companies. While the ruling was only for 5 million dolllars it shows that Bedrock may be successful in suing many others who use the Linux kernel. It could open the door to more software patent trolling.
The troubling thing about the ruling is that the use of the Linux kernel on Google’s servers was considered infringing. Bedrock could use this ruling as grounds to file suit against a huge number of open source users who use Linux effectively taxing anyone who uses the software. Oddly enough the patent lawyer responsible for the activities of Bedrock in this instance also works with PubPat, an organization that works against undeserved patents and bad patent policy. This is either highly ironic or a shrewd attempt to make a public example of how flawed the current patent policies are. But, as things stand now Google has been trolled to the tune of 5 million.
The docket naming other defendants in the case can be found here.
This week’s iPhone controversy is a big deal, but it also could be a win for consumers. Normally, to find out the information about you that your carrier has already taken and is now selling to law enforcement agencies, you have to sue them in court— but with the iPhone, at least, you yourself also own a copy!
Was the iPhone location tracking file an egregious error, especially since they didn’t notify users? Probably. Will it be patched, never to be seen again in the next version of iOS? Probably. But that’s a bummer for people that like owning their own data.
If a business collects data on consumers electronically, it should provide them with a version of that data that is easy to download and export to another Web site. Think of it this way: you have lent the company your data, and you’d like a copy for your own use.
That sounds a lot like what you iPhone location file is. One of the stink bombs thrown up over this iPhone debacle is, “this information isn’t behind a firewall.” True— which means that YOU own it, instead of your phone company. Besides, lots of private information up behind a firewall just creates another juicy target for a hacker (a la Epsilon’s data breach). Are we really getting to the point where we don’t want users owning their own data because they’re so incompetent they might get hacked? Even Thaler’s semi-paternalistic book Nudge doesn’t go that far! Besides, as David Pogue points out,
The one legitimate concern, therefore, is that someone else with access to your computer could retrieve the information about your travels and see where you’ve been. Your spouse, for example. The researchers also mention “a private investigator,” but that’s a little silly. A PI is going to break into your house to inspect your iTunes backup? If your computer is that accessible, you’ve got much bigger problems.
Most likely, the only person that is really that fascinated about you is… well, you. Pogue again:
Meanwhile, accept it: Yes, Big Brother is watching you. But he’s been watching you for years, well before the iPhone log came to light, and in many more ways than you suspect.
Bearing resemblance to inquisitorial systems, the present patent system lays a lot of responsibility on patent examiners who serve as the primary investigators and judges. With hundreds of thousands of applications a year, it’s no wonder patent examiners are overworked and backlogged. It’s become a tradeoff between quality and quantity, which could be tempered by making the system to be a bit more adversarial. Doing so would require the Patent Office to not only consider the perspective of a patent applicant, who is obviously incentivized to see the application move forward, but also consider the perspective of a highly motivated opposition. While more information may lead to better decisions, it may also require too much work. However, several changes to the current system could be made that simultaneously improve the quality and quantity of patent examinations.
Peer to Patent was a great first step by opening up the process to public input. Outside parties could upload prior art which would invalidate frivoulous patent applications. The next step would be to open up the process further and invite the equivalent of amicus briefs by outside parties who may have an interest in the outcome. They could file explanations of why the patent-pending invention was obvious or somehow unqualified to be patented. This process change would make patenting more in line with receiving other government licenses and approvals that require public hearings.
Google Patents could serve as inspiration for a web application that serves as an automatic adversary against patent applications. The idea would be to run the claims of patent applications through Google Patent search to return the most relevant existing patents and surface possible prior art. It could go further by searching the websites and presentations of patent filing companies to identify possible prior art. It could also expand the search automatically to academic journals and online press. All of this information could be compiled automatically into a succinct dossier for the patent examiner to start the examination with.
At some point, Peer to Patent could get more social by actually automatically inviting parties to oppose an application. It could identify businesses and parties affected by a patent application by searching for related patent filers and holders. It then would mail or email the relevant parties about the patent application and solicit opposing arguments or prior art.
Of course, all of these changes rely on valid and meaningful information being provided by opposing parties. Requiring a nominal fee for accepting 3rd party material would help discourage frivolous information from being submitted. Certifying information to be true under the threat of federal criminal charges of perjury will also discourage false information from being submitted.
If all these technical and procedural changes aren’t enough, a simple legal change could make a huge difference. In actual patent lawsuits, the current legal standard for throwing out a patent is “clear and convincing” evidence that a patent is invalid. Microsoft is currently arguing the standard should be lowered to simply a “preponderance of evidence” as is the case in civil lawsuits. Lowering the bar would make patent lawsuits much more focused on the validity of the patents in question. It would actually bring patents into the adversarial legal system we already have.
All in all, the patent system would have much to benefit from a progression towards a more adversarial process. Does anyone disagree or does everyone accept my findings which are based on a cursory examination of the facts?
Victor Wong is the author of two patent applications for online advertising related technologies.
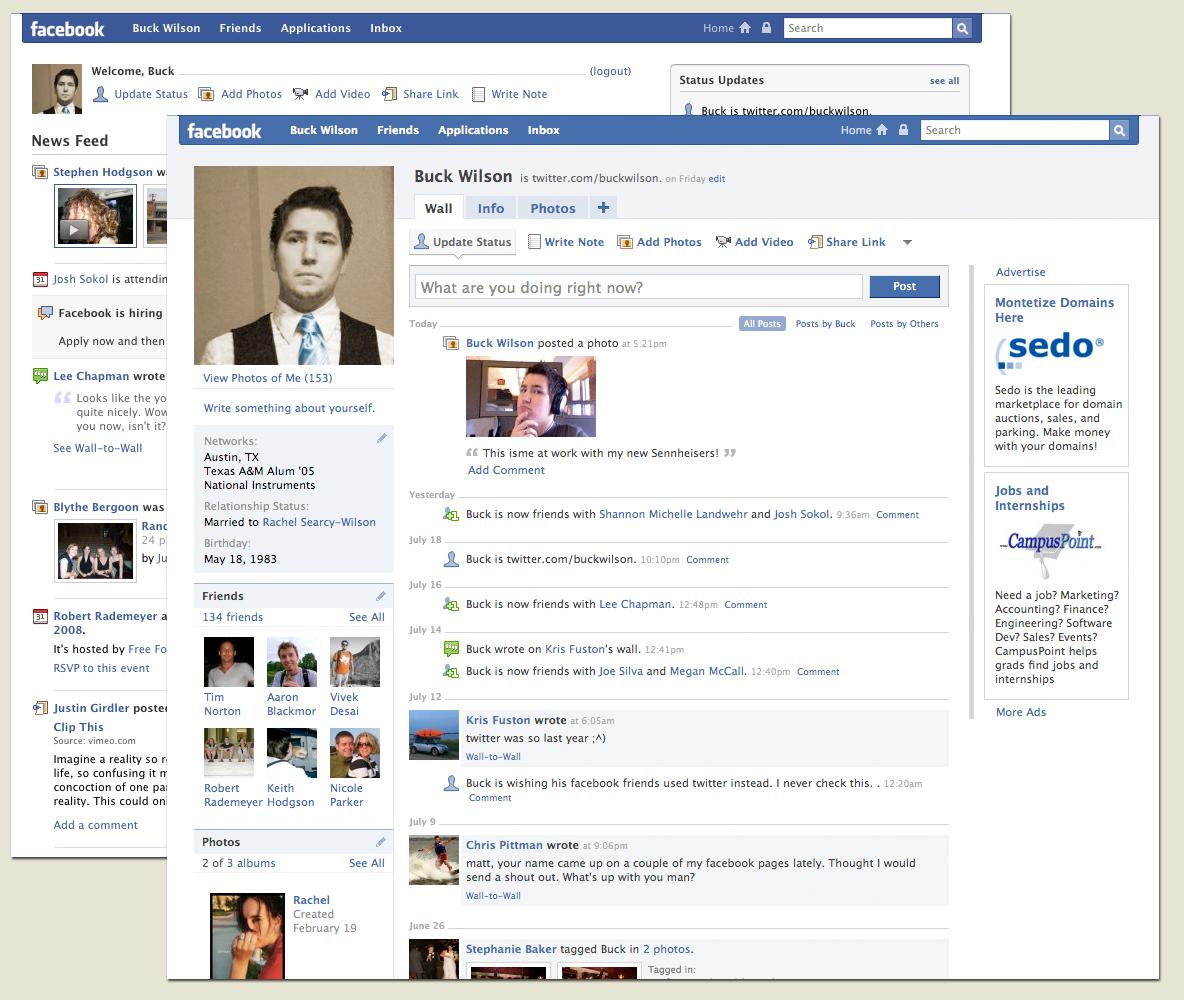
Facebook. The social network. The site that we all (well, most of us) use and love (or tolerate, at least). The site that some of us even name our babies after. Since its inception in 2005, Facebook has gone through an evolution that has moved it from being a networking site shared amongst students at Harvard to a global phenomenon used by 1 out of every 13 people in the world. For me, it’s more difficult than it should be to remember past versions of the site. I’ve been on Facebook since May 2007 (a few months before I started college), but when I think of the way Facebook looks, I can only recall the current design.
I think this is how it looked before the recent changes…I honestly can’t really remember.
Anyway, every time that Facebook performed a revamp of its site, they also made a less apparent change—they adjusted the default privacy settings. This is important as many people on Facebook have probably never checked their privacy settings and just accept the default settings, whatever they may be. In that sense, it’s very interesting to think about how Facebook has changed the default privacy settings over time. Just like the old site interfaces, it’s difficult for me to recall old Facebook privacy options and defaults. Luckily, there are a number of informative sites that do just that.
About a year ago, Kurt Opsahl of the EFF wrote an informative article entitled “Facebook’s Eroding Privacy Policy: A Timeline” which gives us an idea of how Facebook’s privacy policy has changed over time. The differences become pretty apparent when you compare the 2005 privacy policy:
“No personal information that you submit to Thefacebook will be available to any user of the Web Site who does not belong to at least one of the groups specified by you in your privacy settings.”
to the privacy policy from April 2010:
“When you connect with an application or website it will have access to General Information about you. The term General Information includes your and your friends’ names, profile pictures, gender, user IDs, connections, and any content shared using the Everyone privacy setting. … The default privacy setting for certain types of information you post on Facebook is set to “everyone.” … Because it takes two to connect, your privacy settings only control who can see the connection on your profile page. If you are uncomfortable with the connection being publicly available, you should consider removing (or not making) the connection.”
If the change isn’t apparent enough from the text, Matt McKeoncreated a handy infographic that illustrates how Facebook’s default privacy settings have changed over time. You should go to his site to see the full interactive infographic, but take a look at the difference between 2005 and April 2010:
Woah.
The changes are clear, and to be honest, somewhat alarming. Currently, the majority of the information found in one’s profile—one’s wall posts, photos, likes, etc.—is visible to the entire internet by default. Only friends can see one’s contact information, but Facebook would have no privacy whatsoever if contact information was available to everyone. However, with so much other information out there in the public, it is entirely possible that someone could still glean one’s contact info from the site. As Facebook has expanded, becoming not just a site for Harvard students to interact on but a site for literally everyone to interact on, it seems logical that Facebook might increase the default privacy settings, as there are many more people with access to the site that one would want to keep their information private from. Back when the only people on Facebook were your classmates, having conservative privacy defaults probably was not as big of an issue as it is now, when anyone in the world can use Facebook.
Of course, not all of these changes are Facebook being evil; rather, it seems that some of them are the result of Facebook simply being ambivalent about one’s privacy. A lot of the expansion in the infographic comes from the fact that Facebook’s audience has greatly expanded since 2005. Back in 2005, there was no such thing as a “public profile” that everyone on the internet could see—you were either on Facebook (and you could only get access if you were in a select group of people) or you weren’t. As Facebook has opened up to more and more people, rather than “pulling back” on privacy settings to maintain the privacy that Facebook had when it was much more exclusive, Facebook has simply let privacy slide along with the site’s access. Perhaps this is due to Mark Zuckerberg’s lack of understanding about people’s desire for privacy. Even in Time’s “Person of the Year” article about Zuckerberg, it said “Zuckerberg has a talent for understanding how people work, but one urge, the urge to conceal, seems to be foreign to him….Sometimes Zuckerberg can sound like a wheedling spokesman for the secret police of some future totalitarian state. Why wouldn’t you want to share? Why wouldn’t you want to be open — unless you’ve got something to hide? ‘Having two identities for yourself is an example of a lack of integrity,’ Zuckerberg said in a 2009 interview with David Kirkpatrick, author of The Facebook Effect.”
Zuckerberg’s comments stand in stark contrast with the themes of our class. This week, we read Warren and Brandeis’s The Right to Privacy, which states “The intensity and complexity of life, attendant upon advancing civilization, have rendered necessary some retreat from the world, and man, under the refining influence of culture, has become more sensitive to publicity, so that solitude and privacy have become more essential to the individual; but modern enterprise and invention have, through invasions upon his privacy, subjected him to mental pain and distress, far greater than could be inflicted by mere bodily injury.” The real question is, can we use Facebook and cell phones and all the other facets of the modern age and still maintain our privacy? Naturally, we must be willing to give up some privacy simply by virtue of using a “social networking” site. Yet, at the same time, we shouldn’t have to give up more privacy than necessary. Perhaps Facebook shouldn’t be allowed to use an opt-out system of privacy, where most of a user’s profile is shared with the entire internet by default and the burden of selecting more restrictive privacy settings is placed on users. Perhaps, through legislation, we can put the burden on corporations like Facebook, so that the default behavior of the site is in users’ best interests, not Facebook’s. After all, Facebook is a social networking site, existing for the people who use it to communicate and connect; it has no one but its millions of users to thank for its success.
Today, Alasdair Allen and Pete Warden announced that “[e]ver since iOS 4 arrived, your device has been storing a long list of locations and time stamps.” Your device’s longitude and latitude have been recorded hundreds of thousands of times with timestamps getting backed up to iTunes, transferred to new devices and restored across backups. It’s not encrypted, it’s not protected, and it’s pretty easy to access.
A visualization of iPhone location data, from Alasdair Allan and Pete Warden
Let’s recall US v. Maynard, a 2010 case where FBI agents planted a GPS tracking device on a car when the car was on private property, and then recorded its location every ten seconds for a month without obtaining a warrant. The US Court of Appeals for D.C. held that obtaining such information required a search warrant, and rejected the Bureau’s claims that their actions didn’t constitute a search. The Bureau cited US v. Knotts, in which police used a beeper device to track the discrete movements of a suspected conspirator’s car over a limited period of time. In this case’s opinion, the court only addressed the use of such tracking technology for a single car trip–not limitless access to GPS data, regardless of previously specified time or place.
Accessing aggregated GPS data in an investigation constitutes a search and requires a warrant. However, we’re only familiar with this situation when a third party is seeking that location data. What’s unique about Apple as the original collector? They’re not going after data collected by another party–it’s a function built into the software, and it’s covered in the terms of service.
To provide location-based services on Apple products, Apple and our partners and licensees may collect, use, and share precise location data, including the real-time geographic location of your Apple computer or device. This location data is collected anonymously in a form that does not personally identify you and is used by Apple and our partners and licensees to provide and improve location-based products and services. For example, we may share geographic location with application providers when you opt in to their location services.
So what’s next? The blogosphere is feeling squeamish, but is that the extent of the response? Thoughts, guys?
As an aside, Apple’s capitalizing upon the buzz with advertisements on Google, perhaps employing the same publicity tactics that BP did, post-oil-spill (I blogged about it here). I’d be interested to see if the content of these word-triggered ads changes to be more actively positive in Apple’s favor as more eyebrows are raised in response to this latest discovery.
An undetermined number of months ago, I was browsing the internet as I often do, and I stumbled upon a pretty interesting ad for Samsung. While it may require a thick stomach toward some adolescent humor, it was very well done and even a bit inspirational.
Attack helicopters and uncomfortably misogynistic depiction of bosoms aside, I found myself fascinated by the technique of taking something traditionally two-dimensional and making it three-dimensional. I’d since been developing a sense of just how animation and special effects are done, and I never could shake that 3D image of the Girl with the Pearl Earring fighting secret agents, so I eventually I tried my own hand at doing what Samsung had done. It was a simpler take on the idea, with fewer models and no sound, but it’s an project I’d become quite proud of.
The piece it’s based on is M. C. Escher’s Hand with Reflecting Sphere*. This is unfortunate.
You see, there is a key difference between Hand with Reflecting Sphere, and the famous historical paintings featured in the Samsung ad. Hand with Reflecting Sphere wasn’t printed until 1935, which is well after January 1st, 1923. Thus, the piece wouldn’t conveniently turn out to be in the public domain. This was by no means my only encounter with copyright infringement. Oh, not even close! In high school I had made a music video for a song called Haitian Fight Song by Charles Mingus about two students fighting with trash pick-up sticks, and later on I’d make a reckless driving PSA using images and footage found entirely online without paying the rightful dues to their original author. Nevertheless, my teacher at the time, the wonderful Mrs. Gaulke, encouraged the infringements because for whatever reason, those images and that song brought about some creative impulse in me, and in her mindI was growing as an artist. Throughout the years I couldn’t separate myself as an artist wanting to create something new from myself as a spectator constantly influenced by the images and art around me, and the spectator in me would always try to gauge how exactly a certain song or image or reference could alter a film piece that I was working on.
Perhaps it’s my own lack of originality, or perhaps there are many other filmmakers like me that break copyright laws with the purpose of making something interesting and original. If the initial purpose behind copyright was to encourage creativity, then certainly any proposal for copyright reform should take a look at how modern filmmakers treat copyright.
Browsing various video uploading sites and video aggregator sites alike, it’s clear to find that copyright concerns are not highly regulated. There are plenty of montages of celebrity photos and clips ripped from television stations, but these are not the users that copyright laws were meant to encourage because these videos simply take another person’s work and recreating it. However, videos that take an artist’s work and recontextualize it so that it works towards an entirely new project don’t belong in the same category. Take Skyler Page, the mind behind Crater Face.
Skylar is an animator with very few short films to his name. For the most part, he has a series flipbook animations and silly live-action shorts about animating on his youtube channel, most of which only have a few hundred hits. He is by no means a large name, and it’s doubtful that he supports himself on his art. In other words, he’s in the same situation as so many aspiring filmmakers, yet he managed to create a deserved hit with the above video. Nevertheless, the video appears to infringe a copyright by using the Dan Deacon song Pink Batman, and for the purposes of this argument, we’ll assume that it does.
Hopefully one can understand that it’s the freedom of choice in selecting a song which allowed Skylar to experiment. By ignoring copyright, he was free to make precisely the video that he wanted. Now of course, no copyright reform would have allowed Skyler to use a song only three years old without paying some sort of royalties, but in an age in which it’s so simple to use another person’s copyrighted material it’s an inevitable fact that artists will use others material. Regardless of the current, past, or future legality, the appeal of this freedom of choice is impossible to ignore for anyone that calls him or herself an artist.
Current copyright legislation seems to see this current culture of misuse as a growing threat, and reform is targeting the same mentality that I just deemed to be inevitable. Rather I believe copyright reform should do more to understand the usefulness of this freedom of choice. Whether or not that means increasing the number of works in the public domain as proposed with the Public Domain Enhancement Act or lessening the gravity of the proposed punishments for copyright infringements it doesn’t so much matter because there will inevitably be people breaking the law regardless of how it’s reformed. Although if there copyright reform allowed for my three-dimensional M. C. Escher Orb to live in its hole of the internet without fear of a takedown notice, that’d be just fine by me.
As Charles Kenny shouts in the headline of his latest entry to ForeignPolicy.com, U.S. cartoons are holding the developing world hostage via copyright reforms that cripple creation while strengthening copyright holders’ dominance. That is to say, no one in the world (that expects to stay in good relations with the U.S.) can build upon the creations of U.S. companies until those creations fall into the public domain and with the recent barrage of extensions to the length of copyright protection, that’ll be awhile.
[I release the above cartoon into the public domain for you to do what you will with it…but I can’t swear that Disney won’t sue for the use of gloves on my characters. hmm…]
As anyone worried about finding a DMCA notice on their virtual doorstep knows, copyright is complicated, and it’s only getting worse as large corporations continue to push copyright laws down a road of vaults and locks on all things they see as being profitable. But if copyright as it stands is complicated, reform may be even more complicated. As typically happens anywhere a governing body forms, the good intentions of an original system slowly get twisted, bound, reinterpreted, edited, and otherwise convoluted so that no sense of the original intentions can be derived. It’s like a legal mash-up that if subjected to copyright law itself would likely fall under fair use since the derivative is so transformative…but it’s not often healthy for society, and its definitely not where the framers intended it to go.
For instance, New Zealand just passed a bill that could terminate internet accounts if their respective holders can’t prove that they didn’t file-share copyrighted materials. It’s a bold ‘guilty until proven innocent’ move that puts large corporations on top of the file-sharing game while simultaneously threatening internet users’ lifestyles by putting their internet phone, mail, and business functions on the line. It’s reasonable to ask, how would someone defend against an accusation of file-sharing in New Zealand? Can you image having your internet disconnected leaving you without email, Skype, search engines for an unknown quantity of time for something that perhaps you simply couldn’t defend against? Something tells me we haven’t heard the last of this one but it nevertheless begs the question, were copyright holders ever intended to have the right to cut infringer’s connection to the world off for an offense? That’s an incredible power! The next think we’ll know, anyone found to be plagiarizing will be banned from reading books. That’ll improve society.
While copyright law may have initiated as an incentive plan for all creators, more and more stringent and restrictive copyright laws now show that copyright today only stands to ensuring compensation for copyright holders–which often [sadly] isn’t even the creator. This message strongly opposes that which copyright classes around the nation enforce–that copyright law is not intended to ensure one ‘makes money’ off of creations but rather incentivize the production of new works through ensured limited control over the use of those works. Well given all the copyright reforms in the works, good luck convincing students of that in the future!
It seems that law makers around the world have forgotten that culture is collaborative and therefore creation is always going to build upon prior creations. Hence, incentivizing creators by giving them rights to control how their work is used for a limited amount of time, gives the creators an upper hand on furthering their own creations–which at one point was a great source of pride and yes, sometimes revenue but not necessarily the latter. But, of course, this was always meant to be a temporary right to control because the longer items are kept out of the public domain the fewer building blocks other creators have to build upon and that inherently slows the advancement of creations. Law makers seem to have forgotten that part. Instead of coming back to the goal of optimizing the creative environment, more and more governments are simply creating civil deviants out of our culture’s creators by punishing them for being influenced by those who come before them.
And now not only will they be civil deviants but they may be angry, disconnected deviants in New Zealand should they be found to say, file-share a mash-up of their favorite recordings.
Good move out there, governments! Allow our prisoners access to the internet but not file-sharers; that’s just logical! These are the criminals that are ruining our society [file-sharers]! Cut off their access to the world until they come up with a spontaneous stroke of genius that creates their own copyrighted creation over which they may hover.
Sounds like we’re on the right track. [Check, please!]