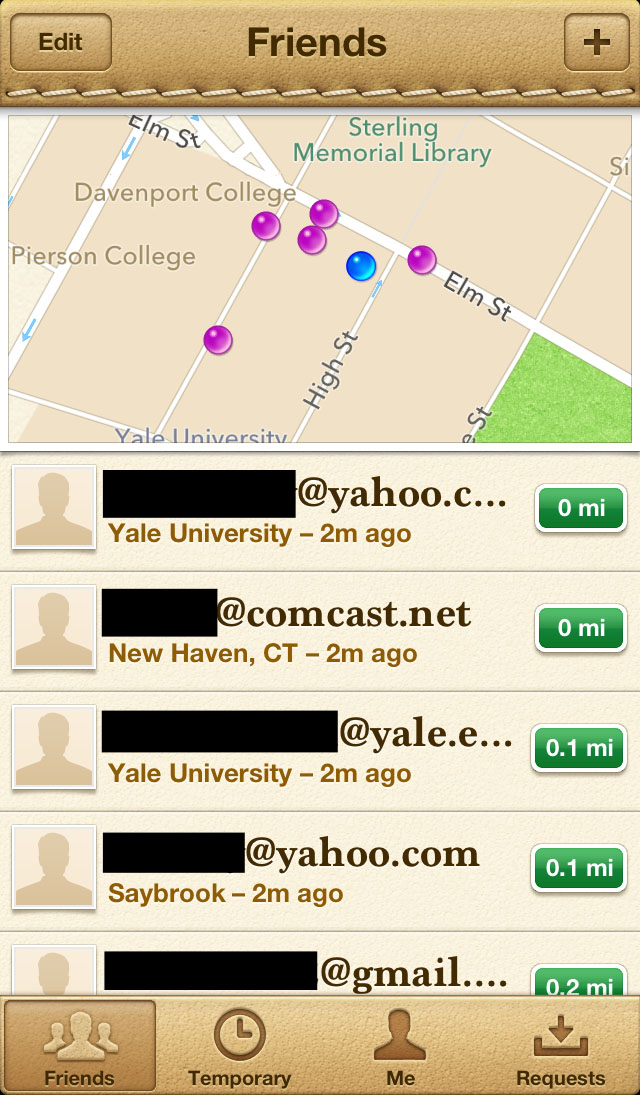
When people find out about Apple’s Find My Friends app for the iPhone, they usually say, “That’s pretty creepy.” They then immediately download the app onto their phone.
Find My Friends takes location sharing to its inevitable conclusion. You know how it’s always such a pain to have to update your location manually (on Foursquare, Facebook, or Twitter) whenever you arrive somewhere in order to let your online friends know where you are? Well, Find My Friends solves this problem with a simple solution: it shares your location with your friends, all the time. That is, if you add a follower on Find My Friends, he will be able to look up where you are at any time of the day, without alerting you that he’s checking up on you. (I think Google Latitude does the same thing as Find My Friends, but does anybody actually use that?)
The implications of this app are incredible. To be honest, over the course of the month that I’ve had it, I’ve really enjoyed this app. I don’t have to text friends about getting to lunch or class at the same time, because I can see if they’re already there. And no longer can friends just mutter an excuse about “attending to some business” and sneak out of the door on a Thursday night. Sometimes, I don’t even bother looking up from my phone to see if a friend is sitting across the room from me. I just look it up on Find My Friends.
All of this sounds like Big Brother’s wet dream. Who would have thought that people would be not only able, but also willing to share their every movement with others? Who would have thought that locational privacy would be a commodity that we prize so little? Will our GPS data really only be used by us? The sum of our privacy is probably a combination of where we are, what we are doing, and what we are thinking. Find My Friends makes it seem normal to have people always knowing where you are, and perhaps even, by extension, what you are doing.
To point out the madness, I tried to think up a way to tangibly demonstrate the problem of oversharing. The result is this video.
To make this video, I followed two of my friends on Find My Friends over the course of 48 hours (Friday, Nov. 30 and Saturday, Dec. 1) by taking regular screenshots on my iPhone. Then, using Google Street View, I basically made a stop-motion video retracing their steps through New Haven. In essence, I recreated their day (or at least the time they spent outside) through the information I gleaned from Find My Friends. You’ll see that I also threw in a few Facebook pictures to illustrate that using other social media, I can add context to their locations as well.
It’s worth noting that Find My Friends doesn’t keep a log of users’ movements, so I had to manually take screenshots in order to keep track of my friends. If you’re curious, both of the friends are sophomores, one in JE and the other in Saybrook. I’m not revealing information beyond that, but you can probably infer a few more personal details from their various destinations.
I hope that people come away from this video a bit troubled by how easy it is nowadays to knowingly overshare and make your every movement a public affair. I certainly came away from this project with that impression. I also came away from this video with a newfound respect for the editors of stop-motion videos and a lasting hatred of screenshots.

The video’s production was hampered by a number of technical limitations. Google Street View does not cover all of the streets in New Haven, so I had to choose my source material carefully to make sure that nobody had to, for instance, walk all the way down High Street. In addition, my original intention had been to retrace my friends’ movements over two or three weeks, but I cut it down to two days when it became apparent how impractical that task would have been. I had also originally intended to follow four of my friends instead of two, but iMovie had no option for a four-way split screen (this says as much about the problems with appliancization as it does about my technical ineptitude). Finally, the compression artifacts and graininess of the video is due the fact that it was apparently necessary to convert the format of screenshots several times before I could import them into my video.
Finally, it might be worth making note of the blatant copyright infringement in the musical accompaniment of my video. It seems to me that this video could qualify for fair use on the grounds that it is educational and has no effect on the song’s market value, but we all know that YouTube doesn’t care about fair use. I’ll just write “No Copyright Infringement Intended” right here. That should keep those DMCA complaints away.



























{kind=link}
{kind=link}