
Our project was to plan and implement an advocacy and awareness campaign concerning the Stop Online Piracy Act. This piece of legislation, currently being debated in Congress, would place severe restrictions on Internet activities and free speech. The act also restricts Americans’ ability to obtain affordable prescription drugs from abroad. SOPA is the culmination of entertainment and pharmaceutical industry pressure on Washington to place stringent protections on intellectual property, and the resulting draconian measures threaten to undermine the fundamental principles of Internet freedom. The Internet has grown at such an astonishing rate because it has largely rejected harsh restrictions on user activity. SOPA violates the theoretical pillars necessary to the Internet’s functionality, and breaking the Internet in such a fashion would bear negative consequences for individuals and businesses that rely on the Internet’s facilitation of free information exchange.
In formulating our project, we decided that a campaign aimed at students and tailored to their concerns would maximize the effectiveness of our efforts. We thus chose to use Internet and social media based methods of communication, and we concentrated our substantive content on issues most relevant to college students. We did not limit our coverage to these issues though, as we aimed to provide a breadth of information about the bill’s negative consequences. By using social media platforms, traditional media outlets, and two different blogging platforms, we were able to spread our message to many Yale students and provide valuable information about SOPA’s Internet-breaking policies to the campus. We hope the lasting impact of this campaign will not only be to facilitate continuing interest in SOPA’s progress, but also to engender a general sense of vigilance in the form of participatory democracy concerning free speech and Internet regulation that resonates well into the future.
Part 1: Launching a Campaign
Our primary goal of this project was to spread awareness of SOPA and hopefully rally others around opposing it. In order to do this, we tried to appeal to many different groups by using a variety of platforms (Facebook, Twitter, WordPress). We also attempted to broaden our appeal by using satire and humor in addition to more pointed intellectual critique of the legislation. We tried to tap into the very things that SOPA would likely cut into: user-generated content, memes and places where you can share links. While we created a lot of our own content, we also tried to post relevant and interesting articles and sites that others had made. One particularly enjoyable and interesting story involved “The Megaupload Song” that received a takedown request, presumably automated, from some RIAA-related entity (Universal Music Group) because it featured many RIAA artists even though Megaupload (a major file-sharing site) owned all the rights to the video. If you’re curious, the (quite catchy) song can be found on Youtube, and there’s more information here. Also, if you’re into remixes, check out this link.
A major challenge for our group in promoting the anti-SOPA movement was fighting the general Yale apathy and our generation’s apathy that comes with having people constantly inviting you to do things (spamming you). This challenge was exacerbated by finals period, and consequently, we weren’t able to get an Op-ed published in the YDN (as they stop publishing early in December). However, we were able to raise a good amount of awareness as many Yalies hadn’t even heard of SOPA prior to our outreach. Through explaining SOPA’s specific relevance to college students as well as posting some of the amazing articles and content available around the web, we were able to educate (and hopefully inspire) a lot of people.
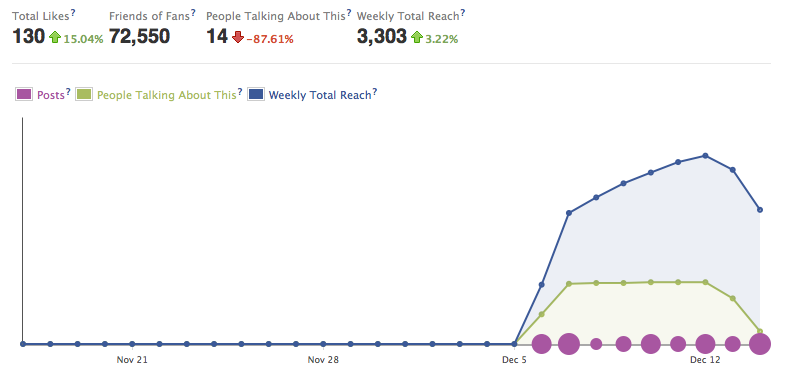
As of this writing, our Facebook page has 130 likes which is equivalent to about 3 percent of the Yale Undergraduate population. While this number is fewer than we would have liked, we speculate that many people for political reasons and/or page like accumulation effects were reluctant to like our page. However, our Facebook page insights seem to indicate that many people still benefited from and engaged with our content. As we see below, our weekly total reach (the number of unique viewers who saw our content from 12/8/11 to 12/14/11) was 3,303 and peaked at 5,191 for the weak ending 12/12/11. Thus, a large percentage of Yale undergraduates likely read something we posted and learned more about SOPA.
To complement our Facebook and WordPress, we created a Twitter account, @StopSopaYale, to complete our social media approach. The Twitter was useful in that it let us keep a small but interested group completely up to date on every #sopa happening. Additionally, the Twitter account was useful because it let us retweet other people’s views and comments on the SOPA debate. This allowed us to combine other people’s opinions with our own and give a lot of different viewpoints on the topic. The Twitter page was also an interesting foray into trending topics and extremely concise posts, a nice contrast to the more drawn out and in depth arguments of our WordPress blog. Currently, we have 20 Twitter followers and we are on the list of one anti-SOPA advocate.
In our opposition to SOPA we took both the pragmatic path into what specifically the SOPA legislation said and would do immediately (and why their is concern about intellectual property protection) as well as the somewhat hyperbolic path, wherein we demonstrated the absurdity of how broadly SOPA is written and speculated on the potential consequences that SOPA could have. In this way, we provided our audience both with a quick draw in (the two line memes and absurd scenarios depicted in videos) as well as further information if they were interested in understanding the issue on a deeper level.
Part 2: A Creative Approach
In raising awareness within the Yale community about the flaws of SOPA, we aimed to create original content which would specifically appeal to Yale students, both in addressing issues relevant to our audience and by presenting this material in an entertaining form. Thus, we created internet memes, videos, an op-ed for the Yale Daily News, and a blog. Additionally, we wrote an anti-SOPA form letter for Yale students to send to their members of Congress which was tailored to reflect a Yale student’s perspective. Finally, to make all of this content easier to access, we either linked the material to the Stop SOPA at Yale Facebook page or we created static HTML pages for the material with corresponding tabs to our Facebook page.
Internet Memes:
The use of internet memes provided an effective and engaging way to point out the ridiculous elements of SOPA. In generating our anti-SOPA memes, we drew from internet memes which were already popular and recognizable, such as the Lazy College Senior or Futurama Fry. Thus, Yale students would be able to easily recognize the humor which we aimed to convey. Plus, internet memes can be easily shared and transformed. Consequently, we hoped that our fans would not only share our anti-SOPA memes, but would also craft similar memes themselves. Some topics which our memes addressed were the possible end to interactive websites such as Facebook and Wikipedia, the end to fair use online, and the halting of future innovative online start-ups.
Video Posts:
Similar to the internet memes, the videos which we created aimed to point out insensible aspects of SOPA in a humorous way. However, through videos we could portray these aspects in a more in-depth form to help our audience gain a better understanding of the problems created by SOPA. For instance, the video entitled SOPA Courtroom Battle illustrates the extreme changes SOPA will make in criminalizing copyright infringement.
Form Letter:
By creating an anti-SOPA form letter, we hoped to encourage students to be active participants in the Stop SOPA at Yale campaign, rather than just passive followers. While creating awareness on campus about SOPA is important, it was equally important to us to inspire a response to the bill. As mentioned above, we tailored the form letter to address the concerns of Yale students. This form letter, with instructions on how to send it, was posted both on our Facebook page and our blog so that it could be easily accessed.
Op-Ed:
As another form of outreach on campus, our group wrote an op-ed piece to be published in the Yale Daily News. Unfortunately, it was too late in the semester for the op-ed to be published immediately, but it can currently be found on our blog and an updated version will be posted in the YDN early next semester. Like our other creative content, the op-ed piece exemplifies many of the problems with SOPA and the article’s sarcastic, comical tone aims to keep our readers engaged and entertained. Also, the op-ed piece directs our readers to visit our Facebook page, AmericanCensorship.org, and Wired for Change.
Blog:
The Stop SOPA at Yale blog provides a forum for our group to express our opinions about SOPA extensively and provides a space for our followers to contribute their own viewpoints. Similar to the op-ed, the blogs are written with the goal of being both informative and compelling. Our blog posts touch on a variety of topics, ranging from the different camps of anti-SOPA supporters to the effect SOPA can have on healthcare. In addition, three of our members held a live blog session to cover Congress’ markup debate of SOPA. Through the blog, our group elevates our position in the anti-SOPA movement: not only do we provide a channel of information to Yale students, but we are also contributing to the online voices against SOPA.
Part 3: Becoming a Part of the Action
One of the more interactive aspects that we integrated into Stop SOPA at Yale was our creation and operation of a live blog. After learning that there would be Congressional debate held to discuss the SOPA legislation on Thursday, December 15 (which just so happened to fall in the middle of our SOPA campaign), we realized it presented a great opportunity to add very direct and significant value to our campaign efforts. We would have been foolish not to somehow take advantage of the fortuitous timing of the most defining event to take place regarding SOPA to date. Sooo, we decided to conduct a continuous live blog during the House of Representatives’ Full Committee Markup. For the sake of clarification or if you are not really sure what a markup is, it is “The process by which congressional committees and subcommittees debate, amend, and rewrite proposed legislation.”
Up to that point, the majority of our campaign’s content was based upon content published online, in the news, by political commentators, activists, etc. We had yet to really dig deep into the real diplomatic activity and reality of what was actually happening with SOPA on Capitol Hill, or among the politicians who will ultimately dictate the bill’s fate. We knew that by monitoring and providing commentary on the live debate IN CONGRESS, it would add a heightened level of authentic value to our campaign.

The very nature and benefits of maintaining a live blog carried unique advantages that fundamentally differed from the other aspects of our campaign (Facebook page, normal blog, memes, creative scenes, op-ed, etc)….
Live blogging gave us a channel to portray not only our opinions about SOPA and why people should take a stand against it, but also the ability to present a discussion based on the statements made by representatives in Congress to support our previously published content. Furthermore, as proactive “Anti-SOPAs,” conducting this event forced us to seriously pay attention to what is ACTUALLY going on with SOPA in the political sphere. When participating in a public protest, it is very easy to get caught up in the overwhelming flood of public opinion online and in the media. Blogging live on the congressional hearing during which political figures delivered their positions helped us stay grounded.
The main goal of our campaign was to engage Yale students in a compelling way. We believed that a live blog would be (relatively) more captivating (to the extent that a live blog really can be) than other forms of content. Our idea was that a live blog on the Congressional markup would attract more attention to the issues we were trying to convey to the student body. We also realized this would make the substance of the debate more accessible. Essentially, we sought to accomplish two campaign goals: 1) more exposure for our campaign, 2) heightened attention and knowledge to students about the bill itself.
We believe we were able to bring the experience of the House debate in an appealing way to those who may not have followed it live, but wanted to have a taste of what went on. The live blog was an aspect of our campaign that probably linked closest with the “real-life” implications surrounding SOPA. The most fitting conclusion I could provide about this endeavor would be – POLITICAL PARTICIPATION AT ITS FINEST!
Part 4: A Rewarding Experience
Ultimately, we deemed our advocacy campaign a success. As is discussed above, our data shows that our Facebook page reached a large number of individuals, both those inside and out of the Yale community. We believe that we helped further the anti-SOPA cause and exposed the weak points of the legislation. It was especially exciting to be involved with the anti-SOPA activity at this particular stage, when the bill is one of its most hotly debated points. This allowed us to piggyback off of other anti-SOPA campaigns’ publicity and allowed us to run a live-blog of the bill’s mark-up in Congress.
It was an extremely rewarding experience for us all, both in terms of educating others about the dangers of SOPA and learning ourselves about the controversial bill, as well as about other related debates regarding the freedom of the Internet. The project also allowed us to gather (or hone) many different skills using technology that we might have never been exposed to, including creating and running a blog (and live blog), creating memes and other internet videos, writing simple HTML, and using and linking Twitter, Facebook, and blog pages. The project was therefore a perfect culmination of our semester in Introduction to Law and Technology, reinforcing and combining new technological skills with knowledge about current Internet debates that in the future will allow us to be better informed and more active citizens of the Internet world.
Mollie DiBrell
Charles Gyer
Sam Helfaer
Nicholas Makarov
Zachary Tobolowsky
Will Kirkland









{kind=link}
{kind=link}
{kind=link}