The Internet seems to care less about privacy than it used to. Sure, there’s a minor uproar every time Facebook is called out on releasing some personal data, but the web isn’t the idealistic bastion of anonymity John Perry Barlow declared it as in the 90s. The key phrase here is every time. People make noise for a few days, then go right back to using it.
At first this seems like a lack of interest, but that’s not necessarily what’s going on. It could just as well be a sign that the supposed breach of privacy wasn’t actually a problem, or that it has been fixed. To their credit Facebook has responded well to specific privacy complaints (see this and this). And even if they hadn’t, the information in question wasn’t particularly dangerous – the worst that could happen is that advertisers get your name and some things you’re interested in.
To me the brief uproars show that people do care about privacy, but it hasn’t yet become a real issue. The phrase “if you’re not paying for something, you’re not the customer; you’re the product being sold” contains a grain of truth, but it’s an overly negative way of looking at the situation. It would be more accurate to say that you are paying, just with your personal information rather than cash. To me this is an acceptable arrangement. Advertising is essential to Internet companies, and if they can make more revenue by tailoring ads rather than making them more obnoxious I’m OK with that. As long as people are aware of the transaction, there’s nothing wrong with the Internet working this way.
That people seem to care less than they once did about privacy and other related tech issues isn’t a sign of growing complacency as much as changing attitudes toward technology. There was an issue in the 90s with the “Law of the Horse” on the Internet, the conflict between whether tech issues should be treated as entirely new or if they can be dealt with using existing laws and social norms. We struggle with this today when we complain about online privacy issues even when the Internet gives us more control than we have in the real world (I don’t mean to say that this invalidates the issue; it’s not unreasonable to argue that the Internet should be a place with more privacy).
As a matter of personal preference, I think the Internet should be kept more private than the outside world. I like that ideas can be judged on their own merit without reference to a specific speaker. But as long a privacy policies are clear, there’s nothing ethically wrong going on here. In my view, what has been framed as a legal or ethical issue comes down to what kind of place you think the Internet should be. This is a difficult question, one that I don’t think a lot of people have thought about, but it’s extremely important. That debate might never definitively end (and it shouldn’t), but if we want to answer the privacy question that’s what we need to talk about.
Who among us hasn’t observed a teacher sneer at the thought of a student referencing Wikipedia over traditional, non-digital sources? These teachers laud the immutability and consistency of books over time; however, this great strength of books can also be a significant drawback: they lack the generativity and adaptability to incorporate changing historiographical opinions, cutting-edge scientific research, and innovative discoveries that a more flexible medium provides. Indeed, while a biology textbook from the 1940’s or an NBA records almanac from the 1980’s is certainly “consistent,” each fails to incorporate new information as it becomes available.
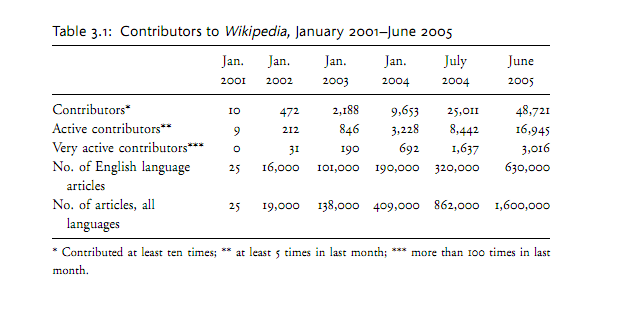
Generativity and informational accuracy don’t have to be mutually exclusive though. Indeed, a study by Nature in 2005found that in a representative set of 42 scientific articles Wikipedia contained 162 factual errors or misleading remarks, while Encyclopedia Britannica contained123. (1) To realize just how remarkable it is that a website that relies on a decentralized, peer-production process could rival an information source with 100 paid, full-time editors and 4,400 contributors, it is necessary to look at the underlying framework of Wikipedia. (2)
Background
Using money earned from his humble beginnings in “erotic photography,” Jimbo Wales sought to create a free, online encyclopedia. In 2000 he conceived of Nupedia, which in the vein of traditional encyclopedias hired experts to write articles. Over the course of 3 years, Nupedia managed to churn out 25 articles. At this juncture, Jimbo Wales sought relief in Postel’s Law (“Be conservative in what you do; be liberal in what you accept from others”) and created a revamped version of Nupedia called Wikipedia, which allowed the general public to create and edit articles using wiki software. The rest is history. Today, Wikipedia contains 23 million articles, spans 285 languages, and appeals to 365 million readers around the globe. Currently, Wikipedia is the most widely used general reference website with 2.7 billion page views monthly. (3) The triumph of Wikipedia over traditional, pay-for-use encyclopedias can be partly attributed to Gresham’s law, which can summarized colloquially as cheap and convenient drives out expensive and high quality.
Wikipedia Model
Encouragement that the Wikipedia model—a model that relies on the collective wisdom of a large number of unpaid volunteers—could be viable was provided by the NASA ClickWorkers experiment, which ran from November 2000 to September 2001. In the experiment by NASA, unpaid volunteers visited NASA’s website to mark and classify craters and “honeycomb” terrain on Mars. (4) The study produced two surprising and interesting results. First, people are willing to engage in an unpaid, novel, and productive experience merely for the fun of it. Second, an amalgamation of data contributed by many unskilled volunteers can be virtually indistinguishable from the output of a trained worker. Thus, large groups of people are capable of producing high-quality work for free.
A Counterintuitive Proposition
It seems hard to fathom that a website that allows users cloaked in a veil of anonymity to edit the content of articles could rival the quality of Encyclopedia Britannica. In an attempt to understand the success of Wikipedia, it is interesting to observe a city in the Netherlands, Drachten. The city has chosen to forgo basic traffic regulations in an attempt to increase safety on the roads. The experiment in Drachten initially has shown promise. Some attribute this to the difference between the effects of rules and standards. While a rule is a regulation that stipulates precise boundaries and is either followed or broken, a standard is more ambiguous and up to interpretation, calling for people to exercise sound judgment. While people might try to circumvent rules that they perceive to be imposed by arbitrary, external forces, they can become more considerate of others when their personal judgment is called upon. As a result, relaxing rules can have the paradoxical effect of causing people to adhere to the desired behavior more closely. (5)
Putting It All Together
So what do NASA and traffic regulations in the Netherlands have to do with Wikipedia, you might ask? These two anecdotes lend credence to the basic assumptions of the Wikipedia model—that the general public is capable of yielding nearly scholarly work with minimal regulation. While the notion of many small contributions forming a remarkable finished product seems strange with respect to encyclopedia articles, consider the analogy of evolution: slight genetic mutations over time in individual agents within a population lead to the betterment of the species as a whole. A similar model is used in scientific research: major breakthroughs rest on the small contributions of many scientists. While this model may seem strange for information compilation, it is certainly not novel.
The Good, the Bad, and the Ugly
It is unsurprising that many of the flaws that arise concerning Wikipedia are quickly ameliorated; indeed, Wikipedia relies on the procrastination principle—rather than trying to forecast potential problems, it waits for a particular problem to arise and then fixes it. For example, immediately following initial reports of Michael Jackson’s death, “edit wars” ensued on Wikipedia regarding the veracity of these claims. In response to such edit wars, Wikipedia adopted the three-revert rule, which stipulates that an editor should not make the same correction to an article more than three times in one day. Another example of Wikipedia’s remarkable ability to adapt lies in its response to criticism by a former editor-in-chief of Encyclopedia Britannica, Robert McHenry. When McHenry pointed out that Wikipedia failed to note the ambiguity associated with Alexander Hamilton’s birth year, a mistake of which Columbia and Encarta were also guilty, users on Wikipedia corrected the error in under a week, a testament to how dynamic the website can be. These are just a couple of the controversies that Wikipedia has responded to effectively and expediently. (For more see Essjay Controversy and Wikipedia Biography Controversy)
My Take
When passing judgment on Wikipedia, I think it is important for us to view it in its proper context. Wikipedia is not meant to be a compilation of flawlessly written, perfectly crafted articles. When such a high threshold for quality is set for content, a bottleneck ensues, leading to an inability to cover certain relevant topics of interest. The three pillars that make Wikipedia so desirable—it’s free, convenient, and unparalleled in the breadth of its information—necessarily lead to a softening of stringent requirements for content quality and review. (You can’t have your cake and eat it too…) As an anecdote in support of the incredible amount of interconnected information on Wikipedia, consider a game that I’m sure most people are familiar with: given topic X and topic Y, start at topic X on Wikipedia and get to a page about topic Y in Z clicks or less. As an example, starting at Harvard Law School I was able to get to Lady Gaga in 4 clicks. (Harvard Law School-> United States->American music->American pop music-> Lady Gaga. Can you beat me?)
I do not understand Wikipedia “hata’s.” I think it is a losing battle to try to argue that due to a small number of factual errors (3.86 per article as determined by Nature), (1) Wikipedia is completely without redeeming value. At a bare minimum, I think one must concede that Wikipedia is beneficial for obtaining background information on a topic. To return to my initial anecdote, this rationale should at least preclude a teacher from scoffing at a student who includes Wikipedia in his or her works cited page. (Note that I have almost exclusively adhered to citing Wikipedia articles for this blog post.) If you are personally unsatisfied with the content of Wikipedia articles, you can ignore them entirely, contribute towards improving the articles, or pursue litigation against Wikipedia (although you almost certainly will be unsuccessful…).
Personally, one of my favorite qualities of Wikipedia is that it provides a consistent format across articles that are (at least to a degree) targeted towards the general public. As a student interested in technology and the natural sciences, I often have to read about scientific discoveries that occurred in the last couple of years: frequently, I only have two sources to turn to: the original research paper and Wikipedia (a testament to Wikipedia’s generativity). Bearing in mind the complexity of the topics, I seek to wrap my brain around the concepts by skimming Wikipedia before delving into the highly esoteric research papers. I believe that using Wikipedia in this manner is an appropriate use of the website. While many people possess a take it or leave it mentality when it comes to Wikipedia, I believe that it is important to apply basic common sense and reasoning when deciding whether to use the website—if you can tolerate 3.86 errors in your reading on the Heisenberg Uncertainty Principle, then have it; if not, put your laptop up and embark in the direction of the nearest university library.
Before the internet was the highly sophisticated, well-structured web of everything that we know it as today, the top ten search results for “Adolf Hitler” returned everything from Hitler’s biography to kitlers, kittens that look like Hitler. No joke.
As the internet developed, the web—and all the information it contained—was structured. As the web grew, it became an increasingly attractive resource for people, so they began using the internet. And then more and more followed suit. And finally, even those people who used to hate on the internet joined the internet bandwagon. This phenomenon is described by Metcalf’s Law, named after a brainy hotshot who co-invented the Ethernet (but who also got his PhD at Cambridge Community College). The idea behind the law is simple. It basically states that the value of a network increases (really quickly) as the number of users in the network increases. We can all relate to this trend. After my friend Florian had to go back to Germany after studying abroad at my high school, he told me to get Skype. And then my friend George told me that he had Skype, as did my other friend Danielle. Downloading Skype allowed not only me to contact Florian, but also Florian to contact George and Danielle, and George to contact Florian and me, and Danielle to contact Florian, George, and me, etc. You get the idea. The value of the network grows—order n log n or n2—asthe number of users does.
Before you dismiss this as some esoteric mathematical phenomenon, it might help to remember that this idea is related to a mind-blowing experiment conducted in the Netherlands. The city of Drachten, with a population of 45,000 people, is verkeersbordvrij—free of all traffic signs.
If you’ve ever been to India and witnessed first-hand the anxiety that drivers there are subjected to in spite of all the road traffic signs, you may wonder what could have possessed anyone to propose something so radical.
But after two years of observing the unusual policy, the city witnessed a considerable decrease in accidents, and other cities in Europe began adopting similar policies. Perhaps surprisingly, the lack of strict, formal laws didn’t result in complete anarchy or dystopia. The take-home lesson from Dracthen is that sometimes, even in unexpected contexts, standards are more effective than rules; given how networks—whether road maps or social networks—grow so quickly in value, this observation is particularly salient when constructing the frameworks upon which we build networks like the internet. Instead of feeling burdened with tons of laws to abide by, people can respect each other’s welfare more effectively if they are liberated from them. If people feel like they are part of a social group—they’ve got your back, you’ve got their back—the Internet Gods do their magic, and things just click.
These occurrences are particularly pronounced in peer production (think free software), which consists of three basic steps: producing, accrediting, and distributing content. NASA Clickworkers, a project that basically distributed and crowd-sourced scientific tasks, demonstrated that the web maintains an altruistic, consensus-esque culture. So many people were willing to devote their time and energy to things that didn’t directly benefit them (or at least, not monetarily) that together, their combined computing power surpassed that of the world’s fastest supercomputer. Dang. (Sidenote: Check out more distributed computing projects here. Some of them, like RPI’s project to construct a 3-D image of the Milky Way galaxy, are really cool.)
NASA's Clickworkers project asked volunteers (instead of graduate students and scientists) with computers to demarcate craters on Mars.
Next, our peers have also seamlessly integrated the process of establishing relevance and accreditation into our virtual worlds. I have yet to purchase an item from Amazon without having access to plenty of customer reviews (of both the product and the shipper if I’m buying a used book). Amazon also includes that handy “customers who bought items you recently viewed also bought these items” bit that alwaystempts me into buying more stuff. All of these services are ways of establishing relevance and accreditation. The “related items” pitch by Amazon teases you with stuff that is almost always relevant or related to the thing you’re searching for or interested in, and all the customer reviews help establish the legitimacy of the product you’re thinking about purchasing. These services have been integrated into the internet in more subtle ways, too. Google’s PageRank algorithm (named after Larry Page, FYI) does this. Pages that are linked to more frequently among more popular sites are prioritized in Google searches. Thus, these links embedded within sites are a form of establishing relevance and accreditation. Good websites will be linked to by other good websites more often, thus constructing a kind of peer-to-peer relationship among the sites we find on Google.
The final step of peer production is distribution, which speaks for itself, though it is worth noting that distribution is cheap online. Together, they all form a powerful combination. Slashdot, Reddit, and Yelp all do these things in one form or another. And so does Wikipedia, the king of online peer production.
Needless to say, Wikipedia is pretty darn awesome. It’s grounded in a spirit of reporting in a neutral point of view, not conducting original research, using verifiable sources, and assuming good faith. You don’t need me to praise Wikipedia for you to appreciate it. We’ve all used it, and we will most likely continue to do so.
As a loyal consumer of Wikipedia, I will defend it to great lengths. I also religiously consult Yelp every time I eat out. However, I do think there are some drawbacks to commons peer production—or rather, to its potential consequences. True, even though peer produced projects like Wikipedia have been found to about as inaccurate as Encyclopedia Britannica, it could still be quite a bit more accurate, and the Seigenthaler incident is a reminder of this fact. And true, the Essjay Controversy is proof that such endeavors are not perfect. Those are not my objections.
Peer production begs the question of peer consumption. Is it not unreasonable to venture that peers—even if loosely defined—are consuming those things that their peers produced? Perhaps this is a bit of a stretch. Our peer networks do serve great functions, but relinquishing the asymmetrical allocation of power that characterized the institutional foundation of property also has consequences. That power, traditionally reserved for the owner, itself performed a valuable service in the same way that information (Yelp, what place has good food? Is the service good?) embedded within networks and their collaborative webs do. The absence of those distributed webs allowed those wielding ownership (power) a sense of authority, validity, and legitimacy. The centrality of the information economy served a purpose in the same way the decentralized economy does, but they have different consequences, which are already materializing and are most sinister when we think about our source of information.
Not to get too meta (as this can apply to Facebook itself, not just to the use of Facebook), but don’t tell me you haven’t ever logged onto Facebook at the end of a long day, only to realize two hours later that you hadn’t read the news that morning and just spent a ton of time (during which you meant to do homework) reading a random assortment of articles that your Facebook friends happened to upload. A lot of people joke about getting their news from Facebook, and in many ways, that appears undesirable.
“A squirrel dying in front of your house may be more relevant to your interests right now than people dying in Africa.” -Mark Zuckerberg
Wait, what?!
Conservapedia, a conservative spin-off of Wikipedia, was founded in 2006 in response to Wikipedia’s alleged “liberal bias.” The main page links to other pages including Why does science work at all?, Is science a game?, and The rules of the game. The website claims that global warming is a liberal hoax and that homosexuality is caused, among other things, by liberal ideology creeping into education and by “psychological tactics used by homosexual activists.” In all seriousness, propoganda has always existed, and it will always exist. I just fear that, although peer production confers benefits that enhance all of our lives, peer production may also facilitate the degradation of a robust and transparent information economy, especially as we consume the products of peer production in an increasingly personalized internet age. I’d guess that the primary consumers of Conservapedia are “peers” of its producers. No one else would consult it seriously. Peer production may beget peer consumption, and to the extent that we allow it to supplant our high quality sources of information, they are potentially damaging.
“It will be very hard for people to watch or consume something that has not been tailored to them.” -Eric Schmidt, Executive Chairman of Google
Cloud computing is the future, and it may be here sooner than we think. This past June, Google rolled out the Chromebook, its cloud computing clients pre-installed with ChromeOS. The idea is simple: almost everything we can do on our PCs locally, we could also be doing on the internet; on someone else’s computer. Why not strip away all of the excess, and let our computers be small, sexy, and sleek while the heavy lifting is done on “the cloud”?
...and a whole host of legal uncertainty
We could start with the fact that well-acquainted internet doomsayer Jonathan Zittrain would blow a gasket over the loss of generativity, as outlined in Chapter X in his “The Future of the Internet”, where X stands for any chapter number in his book. The minute we start letting someone else tell us what we can and cannot do with our computers, we begin to stifle the very innovation that created the Internet as we know it a.k.a. the best thing evar. Is he right? Who knows. This topic has been in beaten to death this course anyway. There are other relevant issues at hand, such as privacy, and I’d like to examine some of the relevant laws and legal questions associated with cloud computing before we plunge headfirst into the future.
Privacy
This is the Big Issue. The 4th amendment protects us from “unreasonable searches and seizures”. If we recall from Katz v. United States, one component of what constitutes an unreasonable search is whether or not one has a reasonable expectation of privacy. Should I have a reasonable expectation of privacy with my data on the cloud because a Zoho spreadsheet functions just like the excel one on my personal hard drive, or because I’m hosting it on the internet can I not possibly expect privacy? Enter the Stored Communications Acts, part of the 1986 Electronic Communications Privacy Act.
The SCA protects users from warrentless invasions of privacy, or, at least it did in 1986. The SCA stems from a time before the cloud when server space was more expensive, and when all e-mails were downloaded off of the server and onto your hard drive. As such, the SCA made a distinction between e-mails that were less than 180 days old, and e-mails older than this. An e-mail on the server for 180, it was thought, was thought to be abandoned, and someone could not reasonably expect privacy of their abandoned e-mails. Thus, the government can, under the SCA, freely demand anything off the cloud that older than 180 days. Makes sense 25 years later with cloud computer, when the cloud has replaced users local hard drives, and people use 3rd-party servers for longterm storage of their data, right? Didn’t think so. The good news is, this has been challenged legally, and at least one district court has called the SCA unconstitutional in Warshak v United States. The bad news is, the SCA isn’t the only relevant law at stake…
How the government can do whatever it wants
Enter the PATRIOT Act, a new government doctrine which says, in summary, that government can, with regards to getting information, basically do whatever it wants, whenever it wants, regardless of where the the information is stored. That means anything on any cloud is fair game for the government’s eyes. In fact, under the PATRIOT Act, somehow, the US government can get information off a server stored in Europe without a warrant or consent. Whoa. It’s already stopped one major defense firm in the UK, BAE, from adopting Microsoft’s Cloud 365 service, because they are afraid of the US government stealing state secrets off of the cloud, which is something that could happen under the PATRIOT act. Privacy being basically a notion of the past with this law, let’s move on to other legal issues.
Net Neutrality
The future of cloud computing is dependent on strong network neutrality laws that are not yet in place. If you are relying on the internet to provide functionality for you computer, and the internet becomes restricted, so does the functionality of your computer. For example, imagine that your ISP begins to put out a web productivity suite designed for use on the cloud. Should they choose to prioritize or filter data away from competitors on your Chromebook, not only does your ISP limit what you can do on the internet, they are now limiting the basic functionality of your computer. The idea that you are free to hack a device that you own to make it do whatever you want doesn’t really apply when the functionality of your product requires the ongoing participation of your ISP.
Jurisdiction
As we know, jurisdiction already makes things legally thorny on the internet. At any given time, you could be accessing data owned Australians hosted on Russian servers from your laptop in America, and it wouldn’t be uncommon. Right now, however, if an French website gets taken down for violating French laws, it might be upsetting to you if you like to visit that website. However, if your French cloud computing service, where you hold all of your data, gets taken down for violating French laws, it could mean the loss of all of your data. You may be bound by local laws with regards to what data you could be allowed to store on your cloud, effectively limiting what kind of data documents you can have. For instance, while in America the first amendment gives you every right to deny the Holocaust, you may not be able to store your papers saying so on cloud services in Germany. In fact, the a paper you had been writing, editing, and storing on a German cloud, could suddenly vanish, and you’d have no way of getting it back. Scary.
In summary…
The Internet is a complicated landscape legally. Cloud computing has many advantages, like making your data more portable, and allowing your computers to be more powerful. While Google would have you believe that using GoogleDocs is just like using Microsoft Word on your computer, and it may feel that way on the surface, legally the two are worlds apart.
...we really, really hope
In an interview two years ago, CEO Eric Schmidt was asked the question “People are treating Google like their most trusted friend. Should they be?”. His response? “If you have something that you don’t want anyone to know, maybe you shouldn’t be doing it in the first place.” Using cloud computing involves not only entering a complicated legal framework, but trusting your 3rd party cloud source, perhaps the way that Hoffa trusted Partin. For the time being, I don’t use GMail, and my programs, e-mail and data are on my personal hard drive. I don’t see that changing any time soon.
As a suite, we decided to write a rap as an educational piece, lecturing small children about the risks involved in hateful speech and defamatory claims against an individual/others. The introduction begins with a terse explanation of defamation in U.S. law and common defenses in court. Transitioning into the topic of defamation per se, the rap speaks about the difference of defamation per se as compared to regular defamation, specifically, that damages are assumed for defamation per se.
Utilizing celebrity cameos, the rap introduces the four specific instances of defamation per se and continues to provide detailed circumstances under which each could be found applicable or a notable exception. Explicitly, the four categories are allegations or imputations injurious to one’s profession, of criminal activity, of loathsome disease, and of unchastity, which is duly noted in the rap’s chorus.
In addition to the four instances of defamation per se, Internet libel laws are also discussed as a means of exhibiting the relevance of defamation laws in modern culture and technology.
We aptly decided to construct this project as a rap song in order to cast the subject matter of defamation into the medium of aggressive hip-hop, a genre which is often plagued with defamation within its context, thus creating a parody of the genre and of defamation itself – allowing us to discuss and commit speech acts that might otherwise be construed as defamatory.
With much serendipity, we invited many famous artists from the hip-hop industry to spit their game on this track. In a surprising turnout, we were able to have featured performances by The Ying Yang Twins, Chris Ludacris Bridges, Nicki Minaj, Rick Ross, Eminem, T-Pain, Dr. Dre, Jamarius Brahamz, Gangreeeeeeen, and Notorious B.I.G. (posthumously). Unfortunately we could not produce a promotional video due to scheduling conflicts and the fact that one individual is currently deceased. Much to our surprise, our producers have signed a contract for another track to be released in the near future. Follow us on twitter @twitter.com/FratCity.
Some of the readings for the search and seizure cases were rather dense, so I made some animations to get across the major points quickly and memorably. I’ve completed “overviews” for two cases so far and hope to get more in before the final deadline.
In the past there has been a huge disconnect between an average person on the street and their source of information. Once that gap began to close up when people began producing information on the internet, everyone was immediately cautioned not to believe anything they read unless it was said or written by a verifiable source (read: professionals). How could a random, unnamed person compete with Dr. X, who received their PhD after Y number of years of studying and doing research at University of Y?
In November of 2000, NASA set out to see if this divide was appropriate. Clickworkers was a project that had the public identify and classify the age of craters on Mars images from Viking Orbiter. These images have already been analyzed by the NASA scientists but decided to run this small experiment to test two things: 1) can the public handle this level of science and, 2) does the public want to get involved? Their findings would revolutionize the users role on the internet as just a recipient of knowledge. After just six months of being launched with over 85,000 visitors, NASA analyzed the public’s data and concluded that the task performed by Clickworkers “is virually indistinguishable from the inputs of a geologist with years of experience in identifying Mars craters” (Benkler).
Wait, wait, wait…did NASA just prove that internet users aren’t just out there looking to troll and that the internet is more than just a medium for porn?!! Sure, the average user is clearly not smarter than the space geologists at NASA but clearly there is knowledge in numbers. Internet users, when provided with a platform and easy-to-use tools, are a force to be reckoned with. This small project has now set the wheel in motion for one of the most controversial yet most used tool of our generation.
The Rise of Wikipedia
Jimmy Wales’s lifelong dream was to create an online encyclopedia. He initially set out to make Nupedia the old-fashioned way:
In attempt to lessen the burden on the experts, Wales launched a Nupedia wiki which was opened to the public. Just like in NASA’s Clickworker, what happened next completely shocked everyone involved. Within just a few days of its launch, the Nupedia wiki, or Wikipedia as it was dubbed, outgrew Nupedia. Wales, though initially worried about the validity of an encyclopedia created by the people, he saw the potential and ran with it. And rightfully so…
The Five Pillars of Wikipedia
In order for any egalitarian community to work effectively, there has to be some common grounds. Though the members of the Wikipedia community are essentially strangers to one another, it still functions because everyone agrees to the terms set out by the Five Pillars of Wikipedia:
1. Wikipedia is an online encyclopedia
2. Wikipedia is written from a neutral point of view
3. Wikipedia is free content that anyone can edit, use, modify, and distribute
4. Editors should interact with each other in a respectful and civil manner
5. Wikipedia does not have firm rules
The first three principles aim to ensure that users do not stray from the original intent of allowing Wikipedia to be a comparable of information as professionally created encyclopedias like Britannica while the fourth is there to make sure that these strangers do not sink to chaos and the extreme cruelty that normally results from internet anonymity. The last principle is a beautiful reminder that although there is an original creator of Wikipedia, this is essentially YOUR project as much as the next editor. There are no rules because the people who are editing have good intention. This is information for the people, by the people.
Wikipedia has changed the way in which people interact with information. For better or for worst, the general public has subconsciously processed these principles and judge what they read based on the expectation one now has of wikipedia editors to not allow for vandalism and faulty information to stay up for long. There is now a standard that one must adhere to when writing and editing Wikipedia articles. If this standard is ignored, Wikipedia users would catch the error and would self-correct within minutes, hours maximum. The general public no longer takes in information as written and demand that at the very least, this standard of credibility and accuracy to be attempted.
Is Academia a Thing of the Past?
Time and money on education or minutes on Wikipedia at no cost?
Before giving up hopes and dreams of entering this exclusive ranking, think of the importance of having true professional. True millions of users contributing small amounts of time is cool for the layman, we still need the professionals to provide the primary and secondary sources that are necessary for the accuracy of Wikipedia. Projects like Wikipedia and NASA’s Clickworker still need people who know what they are doing behind the scenes. Rather than putting professionals in opposition of users, we could start of a great collaboration — free and motivated “interns” alongside professionals working together to make the world a more knowledgeable place. In doing so, the spread of knowledge is no longer a one-way street controlled by the elite few.
But regardless of this beautiful image, these fear of taking over potential doom of academia and the professional markets that depended on being information privately owned has created much criticism of this open-sourced encyclopedia. As Robert Henry, a former editor of Encyclopedia Britannica, claims “Wikipedia is unreliable because it is not professionally produced.” Professors are also equally against the growing use of Wikipedia because of the threat it poses:
“Why do professors hate Wikipedia so much?”
Many have spread this notion that since it is user-created that Wikipedia absolutely cannot be accurate. NASA’s Clickworker project showed, as well as the self-correcting system held together by the Five Pillars on Wikipedia, have proven after much analysis, user produced does not mean inaccurate and “shallow source of information.” We have yet to move into the era in which Wikipedia is an acceptable source in academic papers but I have a feeling we are not far from it now that it has become much better at regulating and expanding itself.
The Dangers of Wikipedia?
Dangers of the distribution of knowledge for the people by the people? You must be crazy!!! As wonderful as it is that we now can instantly look up information that is fairly accurate, have we created a generation of people unable to retain information? Are we now so dependent on Wikipedia that we no longer feel the need to commit anything to memory? As this XKCD comic suggest, has it all gotten out of hand? It is still too soon to even begin to look at the effect of Wikipedia on society but these are definitely dangerous scenarios that are not too far out of the question. A little support is good but complete dependency on any one source of information can lead to disastrous outcomes.
As students at Yale, it is likely you or one of your close friends has spent some time studying abroad in China. While there, it is likely that they circumvented “The Great Firewall of China,” and if they went while as a Yale undergrad, they likely used Yale’s VPN client service to accomplish this. For us, the Great Firewall falls with just a single click and a NetID.
Twitter has been blocked in China since 2009
In discussing internet censorship, it is easy to get bogged down in discussions of oppressive government control, Web companies and their compliance/defiance, or the inherent civil rights that may be violated, but the pertinent discussion to have before all of these is: Are these governments actually effective in their attempts to censor the internet?
Reporters without Boarders maintains a list of countries which “censor news and information online but also for their almost systematic repression of Internet users,” and bestows the lovely title of “Enemies of the Internet” to them. On this list currently are: Burma, China, Cuba, Iran, North Korea, Saudi Arabia, Syria, Turkmenistan, Uzbekistan, and Vietnam. Each of these countries have a variety of control mechanism in place and are mostly aimed to limit access to information of political opposition, discussion of religion, pornography, gambling, and site about human rights. To determine the effectiveness of these controls, one must focus on each mechanism, and the ease or difficulty of it’s circumvention. The central tactic is that the government limits the access of the internet to the people, often being the sole provider. They then are able to monitor the activity of all the users in the country and can limit access through a variety of methods, most of which have a work around to circumvent.
IP Address Blocking
Technique: Blocked IP addresses are made inaccessible. This is one of the most popular techniques, and the main one that is used to block specific sites, such as Youtube in China. If an IP address is hosted by a web-hosting server, all sites on the server will be blocked.
Circumvention: Establish a connection to a proxy which has access, such as the Yale VPN. A VPN service has the added bonus of being very secure. Another technique is using a Web to Email service, which emails you the text content of a website of your specification.
Domain Name System Filtering
Tecnique: Blocked domain names, maintained in a registry, will automatically return an incorrect IP or fail to connect.
Circumcision: Input the IP address (try hex and octal if decimal doesn’t work) instead of the domain name, using sites such as NSLookup
Packet Filtering
Technique: Ceases transmission after or takes away access if triggered by uses of keywords. In Cuba this technique is extended by monitoring word processors, where upon entry of a dissenting keyword the word processor is closed.
Circumvention: Reduce the IP stack’s MTU/MSS to reduce the content of each packet. If the amount of text is small enough to divide up the trigger words, they will not be detected by the program scanning the string.
Portal Censorship
Technique: Remove specific portals of the internet, such as search engines, making it difficult to find information effectively.
Circumvention: Slowly build up a library of useful domain names and URLs, stumbling from site to site. This one is really annoying to deal with.
As you can see, the effectiveness of these techniques increases when they are used together. For instance, blocking search engines and IP addresses would make it difficult to locate an proxy that would circumvent the IP blocker. However, there is still one tactic that is more powerful than all the rest:
Eliminate Access
Technique: The most extreme case is presented by North Korea, where in efforts to censor information to the public, only specific government officials have internet access.
Circumvention: None
With the exception of the North Korean extreme, there still exists a way to circumvent almost every kind of censorship that these governments impose. How then can we treat these acts of censorship as effective? One has to consider the framework of an insider attempting to circumvent from the inside. We enter this problem with all of our prior tech knowledge and tools. Most importantly we know of the existence of sites that may be restricted in other countries, and we are able to search ways to circumvent them. In many of the countries listed above this is not the case, as another one of the main control measures they take is to limit the information about internet circumvention, by the same techniques of IP blocking or packet filtering. New users in these countries don’t have the groundwork we have from time growing up with unregulated access to information on the internet.
This is the true nature of the control of these countries. It doesn’t matter that they are actually effective in censoring the internet, but that they impede the population. For us American college kids, full internet access is a necessity. We need our daily doses of Facebook and Youtube or else we will go into withdrawal. We will find ourselves circumventing these Great Firewalls within a day or two of entering a country that takes removes access from them. It’s likely that the population of these countries just accept some of their lost access rather than going through the risk and hassle of circumventing it. The long term goal is to impede the users enough, continually making it more annoying to circumvent so that eventually new users do not even know it is possible, and gaining that information is just as impossible. At this point the government has become effective in censoring, even though it is not the censoring technology that accomplishes this.
TL;DR: Some governments suck and try to censor the internet with circumventable ineffective means. The true danger is what happens when people stop bother to circumvent these measures, and give in to the censorship.
The border-blurring brought on by the Internet must just be driving oppressive regimes nuts. How are you supposed to control what information people get their hands on when it’s coming from the other side of the globe at the speed of light from people beyond the reach of your thugs and laws? Well, many such regimes have adopted the tactics of similarly-minded paranoid conservative parents who don’t know what to make of the Internet. If the source is beyond their control, they can at least attempt to block it at the point of entry.
This puts the foreign companies providing the content in a bit of a pickle. They don’t want to lose their market share in the country in question, but they (hopefully) don’t want to facilitate oppression either. Or, they don’t want to look like they’re facilitating oppression. In fact, foreign companies are in a better position than citizens of the country in question, since they’re able to use their economic clout to influence policies without the same risks and restrictions that domestic actors face. So, striking a balance between these concerns is of great importance to the success and reputation of the company as well as the human rights situation in the oppressive country. Here are some of the options foreign companies have:
Cooperate & Facilitate
Do whatever the oppressive government wants you to. Stop doing things they want you to stop, and give them the information they demand.
Pros: You get to continue operating in the country. Market share and profit and stuff.
Cons: You’re doing evil, and everyone will hate you for it. You could also get in legal trouble in the US.
Example: Yahoo!, China, 2004. Pretty much the worst possible way to handle this sort of situation. In 2004, the Chinese government released a document warning journalists about reporting on sensitive topics because of the looming 15th anniversary of the 1989 Tiananmen Square Protests. Journalist Shi Tao sent a brief of this document to the Asia Democracy Foundation via his Yahoo! e-mail account. The Chinese government found out and demanded Yahoo! hand over information about the sender. Yahoo! did it without even asking what it was for. As a result, Shi Tao was sentenced to ten years in prison. Yahoo! was criticized by everyhumanrightsorganization in the book. Congress investigated the incident, and later reprimanded Yahoo! for not giving full details to them regarding the incident. Rep. Tom Lantos (D-CA) told Yahoo! founder Jerry Yang, “While technologically and financially you are giants, morally you are pygmies.” Yahoo! was sued in the US on behalf of Shi Tao and another journalist, and they settled out of court for an undisclosed sum. There still exists a campaign to boycott Yahoo! because of this, and I still refrain from using Yahoo! services. Oh, did I mention they did the same thing two years earlier, resulting in another ten year prison sentence for journalist Wang Xiaoning? And were complicit in helping to convict Li Zhi and Jiang Lijun, two other government critics?
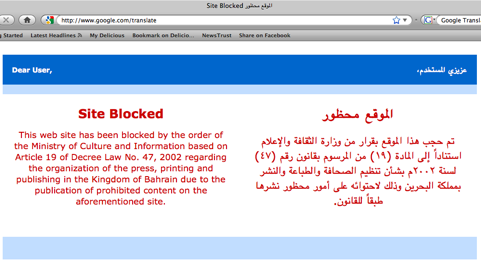
Bahrain's blocked website page
Example: SmartFilter, Middle East. McAfee’s SmartFilter software has been used by governments in Tunisia, Sudan, Oman, the UAE, Kuwait, Bahrain, and Saudi Arabia to block certain Internet content from reaching users. They make no effort to prevent or prohibit governments from using this software, which is allegedly aimed at homes and schools. The software includes a database of more than 25 million blockable websites in various categories. Such filtering databases as well as selective algorithms have been shown time and again to be massively flawed in the categories they attribute to various websites. But, instead of simply inconveniencing a student who wants to research safe sex, AIDS, or religious tolerance (God forbid), it alters the information that can make it to an entire country of Internet users. The OpenNet Initiative also accused Iran of using SmartFilter, though the US’s embargo against Iran would prohibit the sale or licensing of this software to Iran. The company has said that Iran pirated their software. Some say Iran now has its own censorship software. While McAfee doesn’t market their software to oppressive regimes or for the purpose of mass censorship, some selectivity in who they license their software to or the scale at which they allow it to be implemented wouldn’t be a bad idea. It wouldn’t stop governments from pirating it, but at least it would help McAfee from appearing complicit in censorship.
Unfortunately, there are way more examples of this response than any of the responses below.
Cooperate Less
Set a limit to your capitulation while acknowledging the authority of the host government as set out by its laws.
Pros: You might get to continue operating in the country without giving in entirely. You would also help make it clear that there is a limit to what governments can force foreign Internet companies to do.
Cons: The government might still prevent you from operating there. You might not get the benefit of being seen as standing up to oppression.
Example: YouTube, Turkey, 2007. The Turkish government mandated that Turkish telecom providers block access to YouTube because it hosted some videos that were said to insult Mustafa Kemal Atatürk. Nicole Wong, deputy general counsel of Google, which owns YouTube, decided that Google would block Turkish IP addresses from accessing videos that clearly violated Turkish law. Later, though, a Turkish prosecutor demanded that Google block users anywhere in the world from accessing such videos. This is where Google drew the line, and they refused to capitulate to the unreasonable request. YouTube remained blocked in Turkey until 2010 when Turkey’s Transport Minister, in charge of Internet issues, lifted the ban, proclaiming that “common sense prevailed”. So, despite the dismay and limited success of the conservative elements that demanded the ban, internal pressure and the realization of YouTube’s importance prevailed.
Move Services Out of the Offending Country
The more of a company’s operations that physically take place within the offending country, the more power the government can assert over the company. Partnering with local firms presents similar problems. Locating data storage in particular outside of the country allows in-country users to move their data farther from the reach of their government. There are few examples of companies making this kind of drastic business change, but the choices companies make before starting business in other countries affect their relationship to freedom of speech controversies in the future. For example, Google and Microsoft don’t partner with Chinese companies (though they have their own workers in China), whereas Skype and Yahoo do, and the latter companies have lost much more face in controversies surrounding censorship in China.
Pros: It’s likely that the offending country’s government will block your services anyways, but at least the option is there should they choose to unblock them in the future. There’s also the advantage of preserving your reputation and being seen as not doing evil.
Cons: Your services might very well get blocked. Your local workers or former local workers could face trouble.
Example: Google, China, 2010. When Google discovered hacking attempts targeted at the Gmail accounts of Chinese human rights activists, which would put those activists in great danger, they reacted harshly. They announced that they would stop censoring search results on Google.cn, which they had previously agreed to do in order to be allowed to start operations in China. They even went so far as to say that they would shut down their operations in China entirely if the government continued causing problems. While Hong Kong is technically part of the People’s Republic of China, it operates under radically different laws regarding freedom of speech. As is often the case with China’s Internet blocking, the accessibility of Google.cn varies by time and location.
Shut Down Services
No longer offer your services to the offending country and its Internet users.
Pros: You stand your ground, and the offending government will (well…might) think twice before they try to muscle a foreign company again.
Cons: You’re no longer in that country’s market. Whatever limited information or services you were able to provide or would be able to provide are no longer available to users in that country. Your local workers or former local workers could face trouble.
Example: Websense, Yemen, 2009. Websense, like SmartFilter, is web filtering software similar to SmartFilter. Like SmartFilter, it is not intended or marketed to be a tool for government censorship. Actually, it was what my high school used to ban naughty (and not so naughty) things. But, unlike SmartFilter, Websense has an explicit anti-censorship policy under which it “does not sell to governments or Internet Service Providers (ISPs) that are engaged in government-imposed censorship”. When Websense discovered that the Yemeni ISPs were using their software to implement government-imposed mass censorship, they prohibited Yemeni ISPs from accessing updates to their software.
Ignore the Government
There are a lot of services that presumably carry content that oppressive governments wish to block and have probably requested to have taken down, but controversy rarely arises when companies just ignore those requests. It may be useful to be linked to free speech and democracy movements, as is the case with Twitter. Some users will undoubtably find a way to access your website, and it will be much more valuable to them if, when they get there, there is freedom of speech.
Pros: Like the previous several options, you get some good karma by not giving in to an oppressive government. You remain in control of your content. By not engaging the government, the issue may not go any further, and the government may not end up enraged and looking for a way to get revenge or assert its power.
Cons: You may get blocked. You may get in legal trouble if you ignore government requests.
Example: Twitter. Twitter’s strategy is not even engaging with oppressive governments about getting their website unblocked. They focus more on working on developing ways to circumvent censorship. As Twitter CEO Evan Williams put it, “The most productive way to fight that is not by trying to engage China and other governments whose very being is against what we are about.” By continuing to host politically controversial content, Twitter has become central to many opposition movements. Even though it is at least partially blocked in Iran, many Iranian dissidents communicate using Twitter, and a lot of information makes it out of Iran via Twitter.
I shouldn’t need to explain why it’s bad to help government oppress their citizens. So I won’t. But all too often, the moral repercussions of business decisions like these get looked over because they don’t have overt monetary value. But it’s inextricably linked to reputation, which is inextricably linked to success. Part of Google’s success is that it is seen as not doing evil. In a world where people are increasingly wary of big corporations (see: all those “Occupy” movements right now), it’s important that a company be seen as a friend, not an enemy.
OK. Time to open Pandora’s box. Today’s topic? CENSORSHIP.
The idea of censorship is inextricably linked to the concept of information dissemination through the media, be it through more traditional means such as newspapers and television, or, more recently, new technologies such as the Internet. In any case, the act of censorship is also, by definition, associated with some entity that does the censoring.
The first example of a censoring entity that comes to mind (for me at least) is Joseph Goebbels’s Ministry of Public Enlightenment and Propaganda in Nazi Germany, before and during the Second World War. This particular governmental entity (an entity with actual, legal executive power over a large population) is often cited as the ultimate example of a disseminator of propaganda and censorship. Where did this power come from?
Ever since the advent of the first electronic media formats, namely film and radio, it has been relatively easy for governments to control the dissemination of information (barring a legal framework to prohibit such behavior, but we will discuss this later). In other words, virtually unquestionable executive authority and capability to fund high-cost, effective propaganda has often allowed governments to be the censoring entity, as in the case of Goebbels’s Ministry. In the past, the same did not hold true of non-governmental entities. Often lacking in funding or power to affect the masses, businesses, organizations etc. were rarely seen controlling information flow.
Today, more than six decades after Goebbels, things have changed. In this digital age, censorship has taken on new dimensions and applications. With the advent of the Internet, government control over the “masses” has lessened, while big corporations, especially in the technology sector (can anyone guess who I have in mind?) can take part in censoring, or prohibiting censoring for that matter.
But before we move on to specific examples of censorship and its implications today, let’s take a look at the legal ideas and framework behind it.
B. Legal Framework
1) Unconstitutionality
OK. So let’s start with some connotations; Censorship. Media. Information Dissemination. Information suppression. Propaganda. Government conspiracy. Dictatorship. Totalitarianism. I don’t know about you, but none of the above sound really positive to me.
Well, even if you don’t agree, it seems that enough people do since popular opinion holds that censorship is usually bad, excluding certain exceptions. (The links chosen are just indicative; there are many more interesting discussions if one just googles “censorship is bad”). Indeed, most democratic countries have a legal framework (be it in the form of statutes or precedent court cases) that addresses the issue of censorship. In my analysis, I will use only U.S. law, citing specific examples, but the underlying moral and legal principles are more or less the same for all countries.
In the United States, censorship is considered unconstitutional under the 1st Amendment. The First Amendment states that:
“Congress shall make no law […] abridging the freedom of speech, or of the press […].”
Thus, any attempt by any entity to censor information in the media can be found to infringe on the First Amendment rights of the publisher, as “freedom of press” is compromised.
The unconstitutionality of censorship was upheld by the U.S. Supreme Court in a landmark decision in 1971, when it ruled in the favor of the plaintiff of a case that would be come to be know as the “Pentagon Papers” case.
2) New York Time Co. v. United States
In the Pentagon Papers case. the executive branch (surprise-surprise) of the US had sought an injunction against the New York Times, to prevent it from publishing a report on the Vietnam War. The report, entitled “United States – Vietnam Relations, 1945–1967: A Study Prepared by the Department of Defense”, had been leaked by Pentagon analyst Daniel Ellsberg and would humiliate the Johnson administration and the government as a whole if it were published. The Times defended the publication under the First Amendment, leading to a trial that was eventually appealed all the way up to the Supreme Court.
Legally, the Times were in the right; the editors had obtained the material legally, and its publication was supposed to be protected under the First Amendment (freedom of press). Furthermore, the publication of the report would not affect the government’s ability to protect its citizens in any way, so there was no serious argument against publication pertaining to national security.
In a decision which would determine the future of censorship legislation, the Supreme Court ruled that the government had no right to place restraints on the publication of content it sought to suppress, citing Near v. Minnesota: “the chief purpose of [the First Amendment’s] guaranty [is] to prevent previous restraints upon publication.”
3) Exceptions to the Rule
What is a rule without exceptions?
J. Brennan, Associate Justice of the Supreme Court at the time, brings up some very interesting points in his concurrence, concerning specific exceptions where censorship can be tolerated or considered legal.
i) The first and most important exception, Brennan posits, can be inferred by certain past Supreme Court cases, and concerns “a very narrow class of cases”; those affecting national security. Specifically, Brennan mentions that in the instance that “the Nation is at War” or some equivalent situation, “the First Amendment’s ban on prior judicial restraint may be overridden”. But, before it can be overridden, there must be significant “governmental allegation and proof that publication must inevitably, directly, and immediately cause the occurrence of an event kindred to imperiling the safety of a transport already at sea”. In other words, the government must prove an immediate, direct and highly consequential effect on national security. Needless to say, this burden of proof is quite large and not easily met.
ii) The second possible exception (if it can be called that) is the case of obscene material. Once again, this exception arises from another Supreme Court case: New York v. Ferber. The background of the case is not pertinent to our discussion, but the finding is; the Supreme Court held that any material deemed obscene (legally measured by an obscenity standard developed in Miller v. California) can not be protected under the First Amendment. Therefore, any action taken by an entity to censor obscene material is absolutely legal. The reason I mention this rare, peripheral exception now, is that I would like to discuss a modern-day scenario where it applies a bit further down
C. Censorship in the Internet Age
With this legal framework in mind, I would like to discuss four scenarios that have unfolded in the recent past, each of which can help us define the changes in the dynamics of censorship today.
1) Wikileaks: The Richard Stallman of Free Media.
(Please excuse the analogy, but when I thought about the parallels, I couldn’t help but include it).
I start with Wikileaks because it is one of the more clear-cut, legally speaking, situations. In terms of background, the situation differs only slightly from the “Pentagon Papers” case. Indeed, in the “about” page of their website, the editors of Wikileaks directly quote Justice Black’s (also an Associate Justice for the Supreme Court at the time) concurrence: “’only a free and unrestrained press can effectively expose deception in government.’ We agree.”
So what are the parallels with the Pentagon Papers? Well, just like the New York Times, Wikileaks receives its original material legally, by trading for it with secret sources (the methods by which the sources themselves gather the material is legally-speaking completely irrelevant). Furthermore, under the US Constitution, the publication of the material is legally protected by the Freedom of Press clause of the First Amendment.
This being said, there are the aforementioned exceptions to think about. Little if any of Wikileaks’ material can be categorized as legally obscene, so the 2nd exception is out of play. But some of the material released on the site could conceivably have an impact on National security. Indeed, this is the opinion held by many members of the government. But, as Justice Brennan stated in his concurrence, the burden of proof for such a claim would be immense. It would be extremely difficult to prove a direct effect on national security. In the words Robert Gates, former CIA chief: “Is this embarrassing? Yes. Is it awkward? Yes. Consequences for U.S. foreign policy? I think fairly modest.”
In conclusion, barring extreme cases, all Wikileaks material is legally protected under the First Amendment and censoring it is unconstitutional. This is why most, if not all, attempts to persecute the organizations legally have failed (as the editors blatantly boast on their site). In the absence of a plausible case against Wikileaks, prosecutors have alternatively pursued actual leakers (e.g. Bradley Manning), whose acquisition of the material is arguably illegal.
Now for the fun part: the Richard Stallman parallels. While skimming the “about” section of the Wikileaks site, I detected an underlying tone of “rebellion”, for lack of a better description. There was a certain, vague smugness in it, which, to me, suggested a “stick it to the man” mentality. Don’t get me wrong; I don’t for a moment doubt their belief in absolute freedom of press. But at least part of their mission seemed to be fueled by hatred (justified or otherwise) for demonized governments and multinational corporations. Similarly, Stallman has openly rebelled against the big tech-software companies (e.g. Microsoft) by developing the DNU General Public License. And most people would agree that Stallman is at least partly driven by scorn for the big tech companies who “force people to pay for software.
Let’s take it to another level: Stallman’s purpose in creating the GPL was to help software programmers work together and build on each others’ work (promoting the common goal of improving software), without worrying about copyright infringement. Drawing the parallel, Wikileaks editors advocate the cooperation of all media outlets “to bring stories to a broad international readership” (promoting the common goal of complete freedom of press).
These are the most obvious similarities I can think of currently. But I won’t stop here: following is a funny strip from the infamous xkcd webcomic, an obvious exaggeration of Stallman’s ideology: (I cropped part of the comic, as it is irrelevant to the point I’m trying to make; click on the picture to see the original).
And now my own iteration of the picture, rethought for Wikileaks.
For concerned third parties, my alteration of the comic is protected under fair use, since (i) it is for educational purposes, (ii) has some transformative value, and (iii) I have no financial motive.
2) Baidu-Google in China
One of the most discussed issues in the history of Internet censorship has been the Chinese government’s Internet search engine policy. Baidu, the largest online search engine in China, allegedly censors a huge list of “undesirable” sites and searches at the behest of the socialist government (rationalized as “according to the policies and regulations of China”). This censorship includes any content that criticizes the ruling Communist Party, which has led to a global outcry from democracy advocates worldwide. In this case, the entity attempting censorship is once again the government. However, unlike in the past, the government has no direct control over the information dissemination. It must instead rely solely on its executive power, which should influence the true information disseminators (Baidu) to do its bidding. As a side note, a lawsuit was recently brought against Baidu in the US for unconstitutional conduct in “blocking prodemocracy speech from search results”. This lawsuit piqued my interest because it opens up all manners of questions about the extent to which a Chinese organization can be held accountable in the US. But that is a discussion for another day.
The case was very similar with Google, at least until last year. The search engine giant had also been the subject to Chinese regulation, which meant that it was obligated to filter results and censor certain topics (same as those censored by Baidu). In much the same way as with Baidu, the socialist government relied on its executive power to influence Google’s policy. But Google is different than Baidu in one key respect: it is not based in China. Thus, when it decided to move out of the country and into Hong Kong last year (a move that Baidu would be unable and perhaps unwilling to perform, considering its base of operations is in China), it was no longer obligated to censor search results, since the Communist Party’s executive and judicial reach did not extend over China’s borders. Thus the entity that has the power to disseminate and censor information in this case, chose to ignore the latter power.
3) The Arab Spring
The beginning of 2011 saw many rebellions start and take hold in various Middle Eastern countries including Egypt, Libya, Tunisia etc. These are the first rebellions to take place in the era of the Internet, and indeed the World Wide Web seems to have played a significant role in the uprisings. During the rebellion against Hosni Mubarak in Egypt, one activist in Cairo tweeted that “We use Facebook to schedule protests, Twitter to coordinate, and Youtube to tell the world.” Another, humorously tweeted:
As is the case with all rebellions, the local governments wanted to quash the uprisings. Recognizing the significance of the Internet, as well as their own inability to effectively monitor and censor it, some states tried different methods of controlling it. In Egypt and Libya, the government went as far as completely denying access to the Internet as a whole, while in Syria, a government-backed organization severely hacked and defaced several social media sites the rebels were using. These are all, of course, acts of censorship and suppression of the citizens’ freedom of speech, as well as publishers’ freedom of press. Which I guess partly justifies the rebellions in the first place.
4) Google and Child Pornography
I will end on a more optimistic note, with another instance of positive change in the dynamic of censorship (it also relates to the obscenity exception I promised to talk about). In a wholly agreeable step, Google has recently attempted to tackle the problem of child pornography on the Net. It has reconfigured one of its filtering algorithms to recognize and filter certain patterns that are indicative of pedophilic of other such obscene conduct. By practically any and all social norms, child pornography passes any obscenity test, which means that, under the New York v. Ferber precedent, it is not protected under the First Amendment. So, in a sense, filtering such results is not censorship per se, since it doesn’t violate any constitutional rights. Therefore Google can legally exclude all such results from its searches without being sued for suppression of the freedom of press. Once again the entity that has the power to disseminate and censor information has chosen to ignore the latter option. However, this time it is not influenced by another entity (e.g. a government), as it was in the Baidu case, but rather by the social norms (or standard) of the community which would condemn it if it didn’t act so.
D. Conclusion
The advent of the Internet has radically changed the nature and synamic of censorship in the media. While in the past the censoring entity was usually a government, resulting in propaganda, the Net has ushered in a new era. A government’s ability to censor has been radically decreased, now that it cannot directly control the information flow to its citizens (even if it did control the Internet, which it doesn’t, the sheer volume of information on the Web should make monitoring and control it extremely hard).
So who is the new censoring entity? You got it. Big technological corporations that can control information flow over the Internet: Google, Facebook, Baidu. It is easy to demonize these entities, just as it was easy to demonize the propaganda and censorship conducted by governments in the past. Indeed, who’s to say that there aren’t incentives for these entities to censor (e.g. profit), just as there was for governments (e.g. public opinion). We saw that Baidu is basically a marionette for the Chinese government when it comes to Internet censorship. But this is not always the case; we also saw that Google has both declined to censor material the Chinese government asks it to and tackled the problem of child pornography. Definitely better than if the Communist Party was in charge… Don’t you agree?



























{kind=link}
{kind=link}
{kind=link}