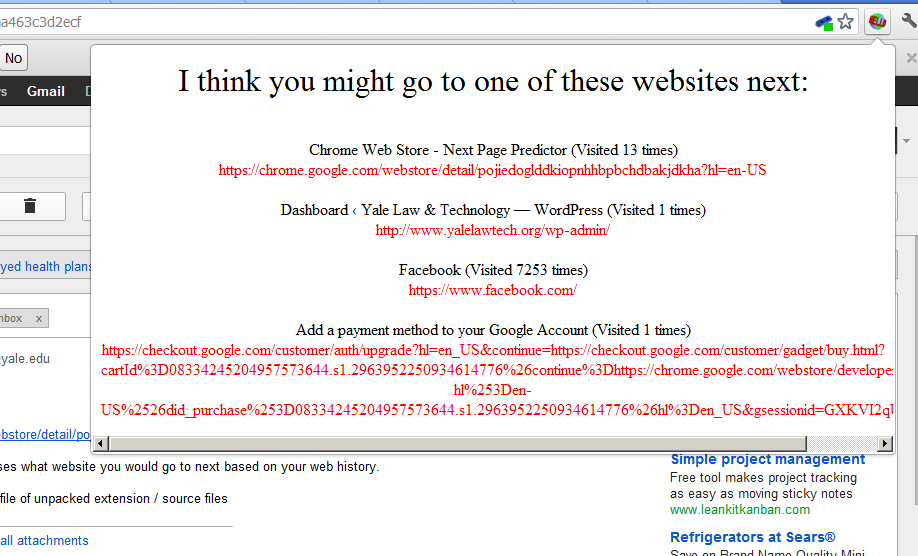
I’ve written a Chrome extension (Download) that has a little fun with your web history. The plugin will attempt to guess four websites that it thinks you are likely to visit next. It does this with the aid of your web history.
Below, the plugin thinks that from my Gmail inbox, I’m likely to visit:
1. This app on the Chrome web store
2. This Yale Law & Technology site
3. Facebook
4. Add a payment method to your Google account
As you can see, the plugin is influenced both by recent activity and larger trends (e.g. Facebook has been visited 7253 times).
Not everyone can read legalese. Websites ought to have clearer, more transparent, and simpler privacy policies.
One important step in this direction is a simple way of summarizing a privacy policy’s features, to make it easy to see how a website will use and protect user data.
Inspired by Creative Commons and the Mozilla Privacy Icon Project, for our final project we have designed a set of icons, as well as simple descriptions, to describe common features of privacy policies.
Additionally, we have built a generator to make it easy for websites to add these icons to their own sites. To further encourage awareness, we have reviewed several popular websites’ privacy policies, so that users can see for themselves how they fare, including Google, Facebook, Spotify, Netflix, and even Yale, among others.
We hope that this will prove useful, and both empower users to really think about the kinds of services they use, as well as encourage the development of a Creative Commons-like standard for describing privacy features, confusions, and pitfalls.
Thanks,
Paulina Haduong
Machisté N. Quintana
Anthony Tordillos
DRM is the natural evolution of copyright protection. As media transitioned into a digital form publishers needed to develop new methods of protecting their works. Some of the earliest copy protections mechanisms accompanied the first generation of computer games. They were usually some sort of gimmicky device or language that often contributed to the gameplay or developed the game’s atmosphere.
Code Wheels from A Secret of Monkey Island. The keys written under each pirate head were required at various points in the games.
Once consumers learned how to bypass these physical copy protections, corporations began using registration keys. These long numerical codes are typically written inside the software’s box or separately mailed. Programs require the code before initially running. Once hackers developed key generators, companies began requiring online registration and authorization, a policy still in use today.
Online authorization was the last step before Digital Rights Management. DRM is unique because in many circumstances it infringes on typical consumer rights and can invade privacy. DRM varies widely between platforms, but most often comes in two forms: a frequent online check between the user and producer for authenticity, and a complex authorization program on the user’s computer.
Common Forms of DRM
Most eBook sellers require all purchases to be linked to a user’s account. Each account can have a limited number of devices authorized to read a book. You must purchase multiple copies of a book to exceed the number of permitted devices. Most retailers allow between four and six activations. While this seems like a large number, the limit is quickly reached if you want to share the book within your family or read it on multiple devices.
eBook DRM prevents sharing among friends, one of the best parts of reading books.
Music was one of the first battlegrounds for DRM. As computers become more common during the late 1990’s and early 2000’s music piracy skyrocketed. Publishers responded by including DRM on CDs, making it far more difficult to rip music. However as digital music players replaced portable CD players this became untenable. People now buy CDs with the express intent of ripping music to their digital players. As this became the norm publishers gradually eliminated DRM from CDs. Currently most physical and digital retailers sell music without any form of DRM.
Unlike music DVDs and Blu-Ray discs still use multiple forms of DRM. DVDs have used a technology called CSS (Content Scrambling System) for almost two decades. While this technology was decoded and circumvented years ago, publishers continue to include it on most DVDs. Blu-Ray discs use a variety of methods to prevent copying. Some require online authorization, while others utilize a complex series of encrypted keys that require a virtual machine to decode.
Of all forms of copy protection DRM for software is by far the most developed. Every major game release is accompanied by the latest DRM. Many publishers have their own preferred form of copy protection. EA typically uses SecuROM for its big releases. Ubisoft recently started using a form of DRM nicknamed ‘always-on’, which requires a user to be continually connected to the Internet for their games to work regardless of whether the game uses the Internet. Any disruption in Internet connection will force the user to exit the program.
The Problems of DRM
While DRM is a justifiable reaction to piracy, in many regards it goes beyond what an average person would consider reasonable. If a product requires online authorization it is only freely usable while the company maintains its servers. Microsoft is a major culprit in this respect. It is stopping all support for its eBook format .lit by the end of 2012. Even though the purchased files will still be usable, Microsoft will not offer any help if problems arise. Microsoft is also discontinuing support for Windows XP, shutting down the activation servers by 2014 and preventing individuals from new XP installations.
Not only can DRM occasionally prevent people from using their legally purchased goods, it can also damage and destabilize a machine. Some forms of DRM install secondary programs on computers to authorize and check software. These programs often require high security clearance. The worst-case scenario is a hacker developing a virus that specially targets DRM, exploiting any security flaws and using it to highjack the computer. Of all DRM programs the most insidious is SecuROM, which installs itself in a computer’s kernel (the system’s core). Removing it requires wiping the entire computer and starting anew. To make it worse, originally EA neither asked nor informed users about SecuROM before installation.
If DRM itself was not enough of an issue, the Digital Millennium Copyright Act makes bypassing DRM illegal. If the company that authorizes your purchases goes bankrupt, the DMCA’s anti circumvention clause makes it a felony to recover you files.
Just like with everything on the Internet, XKCD offers its own take on DRM
How to Fix DRM
This is a tragic cycle perpetuated by a single public outlook. For some reason people do not equate pirating media with theft. The social stigma associated with online piracy is incomparable to that of shoplifting. This dichotomy needs to be rectified before any DRM-less solution can be found.
There is an economic issue fueling the cycle as well. All forms of electronic media are far more expensive than necessary. As publishers have transitioned to digital distribution, costs have dropped but in many circumstances prices have not equally declined. There must be a major incentive for people to stop pirating media. The most obvious one is convenience. Publishers need to make buying their products more convenient than pirating. If prices drop and online distribution methods become simple and quick, people will readily purchase products. Some companies have already instituted such business models.
In the video games industry Steam is the dominant source for digital distribution, holding about a 70% market share. It is significantly more profitable than physical store, yielding a 70% gross margin on sales to the 30% average for most physical retailers. Downloading from Steam is simple and fun. The program runs frequent sales, offering blockbuster titles at significant discounts. While some DRM is included in these products, it is often of the non-intrusive sort.
Typical Reaction to a Steam Holiday Sale. Its business model seems to be doing quite well.
Numerous retailers have developed this type of business model for television, music, and movies. Netflix and Hulu Plus both offer a large variety of television shows and movies for a nominal monthly fee. Their titles can be quickly streamed to any equipped computer, gaming console, or TV. Amazon and iTunes now offer easy and fast movie, television and music downloads, almost all DRM-free. These businesses have made an impact. Music piracy has dropped significantly as a total share of worldwide piracy. While once the majority of bittorrent traffic, music now constitutes only 2.9%. As more companies shift to this model, piracy overall should decrease
DRM is an evil born of our time. As people begin to see the Internet as an extension of the physical world rather than a separate realm social norms should decrease piracy. As corporations shift to more sustainable electronic business models, piracy should begin to disappear. Once both of these changes have occurred DRM should naturally disappear into the annals of history.
Be careful though, because the Zombies are powerful enough to turn you into a Zombie even over the Internet.
—Will Smith, zombie-killing expert, CPSC 183 final project
For our project, we created a Choose-Your-Own-Adventure-style learning course to teach about internet safety for younger generations and hosted it on a website. The site visitor is cast in the role of a high school secret agent attempting to hold off a zombie apocalypse. He or she must make a series of correct choices, which teach various lessons: password safety, login/logout basics, cyber-stranger danger, spam smarts, and spotting phishing. After making a wrong decision, the user is infected and becomes a zombie, joining the ranks of the rest of his generation (who unthinkingly act unsafely on the web all the time). We hope that the spy/ zombie storyline will help our target audience internalize the importance of using caution online.
The necessity for a game/course like this one lies in the fact that today’s moment is one dominated by the Internet. Websites like PleaseRobMe.com remind us just how reckless we’re becoming online―and in a society where young children often have access to the Internet, it’s imperative to educate them on the right way to use it. Our “zombie apocalypse game” is a logical extension of the stranger-danger videos shown in elementary schools in the 1990’s.
Preview: After making a wrong decision, the user is infected and becomes a zombie, joining the ranks of the rest of his generation.
For my final project for CPSC 183 this semester, I wanted to explore the possibility of creating a website that auto-generates a continuous music mashup from song files downloaded from the Internet.
Before I jump into the details of its implementation though, let’s take a step back for a moment.
First, what is a mashup?
A mashup, loosely defined, is a song that is itself composed of several other songs played simultaneously. The songs are played on top of each other in synchrony so that beats match up across songs and, if done well, the result is extraordinary.
Some mashups are simply two songs cleverly woven together and played all- or almost-all-the-way-through, while others feature hundreds of song clips all interleaved over the course of half and hour or more. It is the latter category that I most enjoy (and that I like to fold my laundry to); I find it fascinating how mashup artists can create an entire musical landscape that shifts dramatically over time through the subtle use of other people’s music.
The end of a good mashup is like the last few pages of a great book, or the final minute of your favorite movie: once you get to it you realize how sad you are to have it all come to an end, knowing that no new exciting plot twists or tempo changes await. So, I thought, what if there was a mashup-generator that created mashups on the fly, generating a completely original mashup that could, in theory, run forever?
The mashup is one of the rare mediums in which the consumer (i.e. the music listener) becomes the creator. Mashups, and remixes of all varieties in the general case, take control away from the original musician and give it to anyone with even a passing interest in the medium and access to a computer. I find it fascinating that modern music mashups are entirely dependent upon modern music-editing software, and yet the creators of Logic Pro or Garageband would never be considered even partial creators of a mashup. This is fair—we are a society that rewards output and not the process leading up to it, and it would in one sense diminish the creative effort of the mashup artist to say his/her creation was partially made by a software developer at Apple. These rules extend to all creative processes, and inherently make sense—should the woodworker have to send royalties to the creator of the cross-cut saw and the lathe? Should Mr. Lathe then give money to the inventor of the knife, or the electrical motor; or to Nikola Tesla, or the discoverer or the electron? Clearly this would be absurd.
But the question then becomes: if I could successfully make this mashup machine (cleverly coined “MashupMachine”), who would own the mashups it produces? True, my website wouldn’t save copies of any mashups produced, but 1) one could still record its output relatively easily, and more importantly 2) even fleeting works of art have owners and creators. It’s not as if a sand mandala wasn’t created by a monk just because it won’t last forever.
So is all MashupMachine output inherently my creative work? On the one hand, it’s just a piece of software, a tool, akin to a Garageband. I can certainly be credited for the tool itself, but not for everything created using it. But at the same time, the difference between this program and other tools is this would be completely uninteractive (at least in the initial implementation)—just sit back and listen. In that sense, the situation resounds with the ethical dilemmas of artificial intelligence—if researchers use a genetic algorithm to permutate pieces of computer code until one code produces a new mathematical discovery, most people would say the researchers get the credit. But once you put a face and human-like limbs on the program and have it walk around like in an Asimov novel, I think most people would say the robot gets credit. Is autonomy a factor here? Does the robot need to be able to solve the problem entirely on its own? In that case, what if MashupMachine had vague controls for things like tempo shifts or incorporated song genres?
As we become more and more dependent upon machines and automated processes for everything we do, we increasingly face this question of who is ultimately in control. Sure, Isaac Asimov and Francesca Coppa argue that we’re moving towards a future dominated by specialist producers of “content,” be it music or software or education. And yet what happens when these specialists are resigned to the consumer role, when all content is created outside of human control? Clearly this is an extreme situation not in the near future, but we’re already in a time when automated processes can make inventions and discoveries on their own. I expect in the next few hundred years we’ll see a shifting of the laws governing ownership, patents, and copyrights in one way or another, though it’s unclear where the courts and legislators will rest their gavels and pens.
Will non-human created content belong to a related human? Will it go straight to the public domain? Will it be government property? Will it be something else entirely, not confined to traditional copyright and property laws? We’ll just have to wait and see. In the meantime, why not let computers make us some music?
If you want to know more about how I implemented MashupMachine (to avoid having a gigantic blog post), go here.
Edit: you can see the website here. It definitely works in Chrome but possibly not other browsers, and be patient… it can take a little while to start. Enjoy the cacophony!
A few months ago I was reading an article on TechCrunch about a group of Congressmen that had penned a letter to President Obama in support of the AT&T/T-Mobile merger. Shortly after the article was published, a reader contacted the author noting that one of the Representatives had received over $25,000 from AT&T over the course of his career. Almost immediately the comments erupted with cries of corruption, with one user going so far as to say that “Our Congress is bought and sold by lobbyists.” Of course, this outcry never would have happened had no one taken the time to go and lookup the campaign contribution information. This made me realize that in order for campaign finance information to be useful, it has to be more easily accessible. As long as users have to navigate away from their current task and lookup each officials’ record by hand, the data will go unused by most.With this in mind, for my final project I developed a Chrome extension called Access Influence, with the goal of making campaign contribution data more readily available. Whenever a user is on a website that references a senator by name, a green $ notification appears at the right hand edge of the Omnibox. Clicking this notification results in a popup window containing the names and affiliations of all senators present on the page along with links to their “Top 20 Contributors” pages on OpenSecrets.org.
Available now on the Chrome Web Store
With this extension installed, the barrier to entry for accessing this data is significantly lowered. Still, the angry comments on TechCrunch left me wondering: what affect will the increased access to this information have on users’ perceptions of Congress? To explore this question I created a brief survey in which participants read two articles and answered a few questions. For Article A, participants were permitted to use the extension to research donation histories of the relevant officials, while for Article B they were asked not to. Participants were split into two groups, with one reading Article A first, and the other starting with Article B. The survey was conducted with 20 total participants, 10 in each test group. A few interesting results emerged.
First, it is important to note that among those surveyed, perceptions of congressional-corporate interactions weren’t terribly high to start with. At the start of the survey, participants from both test groups were asked how, in general, they felt about the way that Congress interacts with corporations. Responses fell on a five point scale, with ‘1’ being “strongly disapprove” and ‘5’ being “strongly approve.” The average across both test groups was a mere 2.6, between “neutral” and “disapprove.” After having read both articles and using the extension to research the officials mentioned in Article A, the participants were asked the same question at the conclusion of the survey. By the end of the survey, the average had fallen to 1.7. The distribution of responses are shown in the graph below.
The other interesting result of the survey was the effect that using the extension had on participants’ future opinions. As noted earlier, the first test group read Article A (with the extension) first, followed by Article B, while the second read Article B first followed by Article A (with the extension). After reading each article, participants were asked how they felt about Congress’ interaction with corporations in the context of the article. For Article A, it did not make a difference whether the article was read first or second; the reaction was negative either way.
For Article B however, those participants that read the article after having already read Article A with the extension exhibited a significantly more negative reaction than those that read Article B first.
This seems to suggest that those who use the extension and find a monetary connection between an official and a corporation in one article, could potentially be conditioned to react more negatively to future articles, even if the extension is not used when reading the later articles.
As interesting as these results are, it is important to remember that they could change with a larger, more diverse pool of participants, or a different set of articles. One thing that does seem clear, however, is that there is some level of interest in the functionality provided by the extension; 17 of the 20 participants indicated that they would be interested in using the extension in the future.
This is just the first release of Access Influence. In the coming weeks I will be working to improve the search reliability and efficiency of the extension. I am also working to integrate the contribution data directly into the popup window, and I am experimenting with displaying the data graphically. You can download the initial release of the extension from the Chrome Web Store here. If you like what you see, please consider giving a donation to OpenSecrets.org.
Have you ever been excited to watch a video online only to click it and realize that it’s been taken down for copyright issues? Us too, which is why we decided to do our project on the topic of the DMCA and fair use circumvention. Conveniently, the song “YMCA” by the Village People was ripe for a parody on the topic. The goal in creating the “DMCA” song, music video, and website was to present the DMCA and certain safe-harbor law in an easily digestible format. Too many videos are taken down without true cause, and understanding of fair use arguments as well the the word and intent of the Digital Millennium Copyright Act could lead to more counter-notices and hence a greater pool of video entertainment available to the public.
While the video is not necessarily a parody of the YMCA, per say – it doesn’t comment on the source material itself – we believe the the creation is significantly transformative. In addition to this, we created it for non-commercial purposes and as an educational tool, which makes the fair use argument fairly easy.
Hopefully this website and video will spread awareness of fair use rights. The website and the information and links on there aim to teach viewers the specifics of the law–and fair use, specifically since it’s a concept that is often confused. As Brad proved this semester in our class, often humor is the best way to make learning effective and fun. While our video is certainly a bit silly, we believe the overall message is an important one worth addressing.
The lyrics for the video are as follows (they can also be found on the website):
Young man, I see your video’s down.
I said, young man, there’s no reason to frown.
I said, young man, there are tricks all around
To help get your vid reposted.
Young man, there’s a place you can turn.
I said, young man, there’s no need for concern.
I said, young man, there are loopholes to learn
You can fight that takedown notice.
Well have you heard of the D-M-C-A?
Have you heard of the D-M-C-A.
If you want your work back, well you know there’s a way
In the O-C-I-L-L-A
D-M-C-A.
Have you heard of the D-M-C-A.
If you think in good faith, that their actions were wrong
Listen up to our awesome song
Young man, there’s a problem at hand,
I said young man, you could get yourself banned
So let’s face it, why don’t you take a stand
And just send that counter notice
Young man, you’ll be mocked by your friends,
I said, young man, be like Stephanie Lenz,
And just sue them, then they’ll make their amends
And you’ll be a web sensation
You’ve got to study the D-M-C-A (x2)
If you’re stealing the work, just to sell it yourself
Then your venture won’t turn out well.
You’ve got to study the D-M-C-A (x2)
Just make sure that your use still remarks on the source,
Or the takedown could be enforced
[Music cuts out and video shows a DMCA takedown notice by the Village People]
[Music comes back with a counter-notice on the grounds of non-profit, transformative, educational use!]
Good thing we knew of the D-M-C-A!
Good thing we knew of the D-M-C-A!
Now our work’s back online for the public to see
But there’s problems ahead for me
D-M-C-A
Too bad we knew of the D-M-C-A
Cause this video sucks, and I know it will stay
On my digital dossier
Group: Misbah Uraizee SM’13, Jerome Luo TD’13, Nick Letizio TD’13, Michael Holkesvik TD’13
When Justice Scalia got wind of the online dossier a Fordham Law class had compiled about his personal life using information found online, he was not pleased. “Every single datum about my life is private? That’s silly,” he had previously scoffed. But his tone after the class had done its work was quite different. “This exercise is an example of perfectly legal, abominably poor judgment. Since [the professor] was not teaching a course in judgment, I presume he felt no responsibility to display any,” he remarked after the fact. Harsh, Scalia. Embarrassed?
This change in point of view seems pretty drastic. Whether compiling the dossier was appropriate is an interesting issue, but we took something different away from this incident. Scalia’s heated response posits a question: is what we think about our privacy different from how we actually feel about our privacy?
To investigate further, we designed an Implicit Association Test to examine the implicit and subconscious associations between elements of the online world. Other IATs have yielded controversial results (tl;dr, you’re more racist than you think). The test works by timing subjects’ reaction times in sorting words into two different control categories. The control categories are then combined with two target categories to see which category is more readily associated with which control word. In the case of our experiment, the control words were “safe” and “dangerous.” In the first test, we compared them to “Internet” and “Physical World,” and in the second, “Facebook” and “Google.”
Our experiment produced some interesting results. Most notably, the results highlight the Americans’ widespread wariness of the Internet’s dangers. We hope the results of our experiment will be a useful insight into the minds of Internet users and participants as we continue to forge policy that shapes how we interact with the virtual world. !
Take the test or view our results and analysis at implix.org!
In case you aren’t hip and up to date with the booming tech scene, YCombinator and TechStars are the two best startup accelerator programs in the US. Together, since YCombinator’s first class in 2005 and TechStars’ in 2007, an accumulative 377 new tech companies have passed through their doors. These companies don’t just receive space, free food, and mentorship; earlier this year Yuri Milner, a Russian “Tycoon” whose already invested in Facebook, Twitter, and Spotify, announced that his fund, StartFund, and SV Angel would offer every new Y Combinator startup a $150,000 convertible note. TechStars has followed suit and in September announced that it raised a $24mm fund from the likes of Foundry Group, investors in MakerBot (see classmate Nick’s final project), and RRE Ventures, investors in companies like HowAboutWe and Betaworks, so that every new TechStar’s company receives a $100,000 convertible note upon acceptance into the program. This is tuppence though compared to the combined $759 million they have all raised over the past 6 years.
So you’re thinking about applying? Well you aren’t alone. You might have gotten into Yale but YCombinator and TechStars take exclusivity to a whole new level. Yale just accepted 15.7% of early applicants to the class of 2016. YCombinator though has an acceptance rate of around 3%. TechStars’s first NYC class had a shockingly low 1.1% acceptance rate. Now how about that for exclusivity!
A lot of people have compared TechStars and YCombinator based on startups’ fundraising and exits. A post on TechCrunch last weekend did exactly that and stirred up a heated debate about the respective merits of each program among devoted alumni and fans. Funding though is a metric by which to measure success, rather than an important factor for success.
Time and time again entrepreneurs and VCs say that the team is the most important factor for success. Five time serial entrepreneur turned VC David Skok says that the management team is of critical importance: “A players attract other A players. B players attract C players. Therefore the starting team should ideally be all A players.” Steve Blank, 8 time serial entrepreneur and author of the startup bible, “Four Steps to Epiphany,” says that “team composition matters as much or more than the product idea.” Why? Because “the best ideas in the hands of a B team is worse than a B idea in the hands of a world class team.”
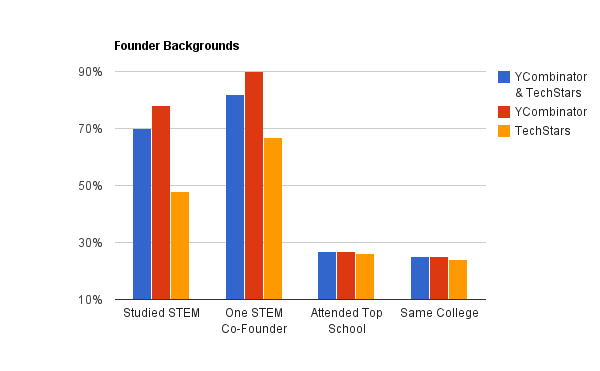
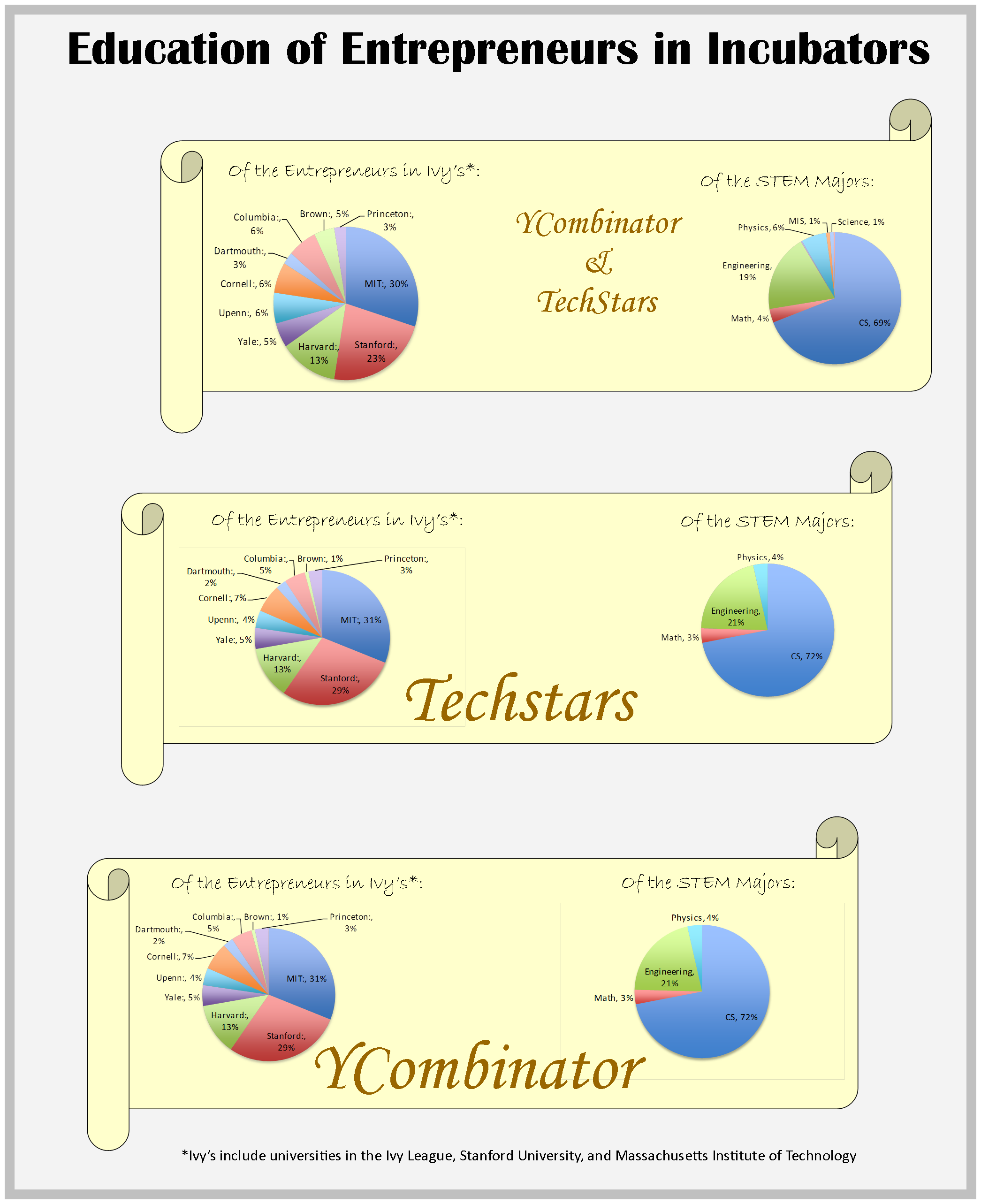
So if YCombinator and TechStars are more exclusive than the Ivies, just who are these A player founders forming the “world class teams” of the future? To answer this we dug up Linkedin profiles for 254 out of the 377 total companies from the past 6 years and documented founder’s college and major. In the process we also have empirically helped answer a long-time question plaguing many aspiring entrepreneurs: can you really be a non-technical co-founder?
Takeaways:
If you want to get into TechStars or YCombinator, and are a Freshman or Sophomore in college, you might want to jump of the cool-kid bandwagon and actually study STEM (Science, Technology, Engineering, Math).
There is definitely little such thing as a non-technical team.
The accelerators might tout that they are more exclusive than Yale, Harvard, MIT, Stanford etc but those graduates make up a non-insignificant portion of startup founders the accelerators accept.
Higher ed is under attack right now by a growing number of people who wonder if it is all worth it. When it comes to YCombinator and TechStars it just might be:
Of all the founder’s whose Linkedin profile we found only a handful explicitly said they were self-taught
25% of co-founders attended the same college – your college network is a powerful community to tap into when you want to find that second A player to start a venture.
Here are more details of the breakdown:
From an investor’s perspective all of this looks like great news: these incubators take an overwhelming majority of true tech people, with higher ed backgrounds, and shower them for 3 months with top-notch mentorship and a wealth of resources that help drastically lower the chance of failure. Oh, and there are clear runaway success stories like Heroku, and AirBnB and DropBox are in the pipeline.
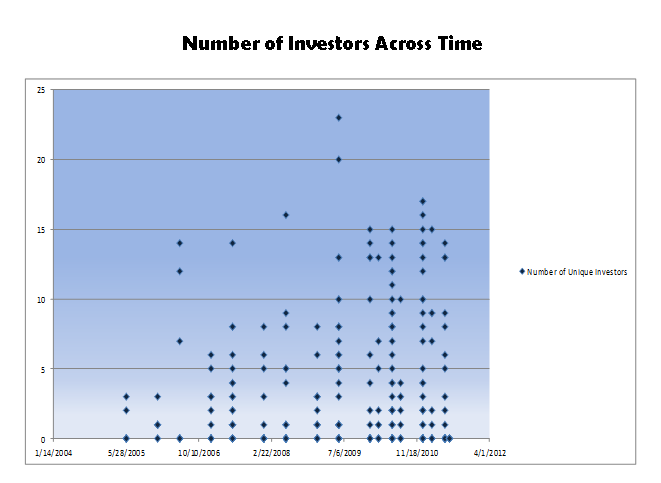
Investors have definitely taken note. In fact, so many have that the whole thing is turning into a feeding frenzy. The number of investors scrambling to participate in early stage rounds has ballooned. Each dot below is a specific company. On the x-axis is when they attended the accelerator, and on the y-axis is the total number of investors throughout the lifetime of the company. Despite being much younger companies, recent accelerator grads have on average more investors even though they will have had the opportunity to raise fewer rounds.
So if you haven’t already switched majors / started watching Stanford’s online CS courses while simultaneously filling out an application to both TechStars and YCombinator, here is one last fun fact: if accepted, there is a chance you could be both the next Steve Jobs and a TV docudrama superstar:
Cloud computing is the future, and it may be here sooner than we think. This past June, Google rolled out the Chromebook, its cloud computing clients pre-installed with ChromeOS. The idea is simple: almost everything we can do on our PCs locally, we could also be doing on the internet; on someone else’s computer. Why not strip away all of the excess, and let our computers be small, sexy, and sleek while the heavy lifting is done on “the cloud”?
...and a whole host of legal uncertainty
We could start with the fact that well-acquainted internet doomsayer Jonathan Zittrain would blow a gasket over the loss of generativity, as outlined in Chapter X in his “The Future of the Internet”, where X stands for any chapter number in his book. The minute we start letting someone else tell us what we can and cannot do with our computers, we begin to stifle the very innovation that created the Internet as we know it a.k.a. the best thing evar. Is he right? Who knows. This topic has been in beaten to death this course anyway. There are other relevant issues at hand, such as privacy, and I’d like to examine some of the relevant laws and legal questions associated with cloud computing before we plunge headfirst into the future.
Privacy
This is the Big Issue. The 4th amendment protects us from “unreasonable searches and seizures”. If we recall from Katz v. United States, one component of what constitutes an unreasonable search is whether or not one has a reasonable expectation of privacy. Should I have a reasonable expectation of privacy with my data on the cloud because a Zoho spreadsheet functions just like the excel one on my personal hard drive, or because I’m hosting it on the internet can I not possibly expect privacy? Enter the Stored Communications Acts, part of the 1986 Electronic Communications Privacy Act.
The SCA protects users from warrentless invasions of privacy, or, at least it did in 1986. The SCA stems from a time before the cloud when server space was more expensive, and when all e-mails were downloaded off of the server and onto your hard drive. As such, the SCA made a distinction between e-mails that were less than 180 days old, and e-mails older than this. An e-mail on the server for 180, it was thought, was thought to be abandoned, and someone could not reasonably expect privacy of their abandoned e-mails. Thus, the government can, under the SCA, freely demand anything off the cloud that older than 180 days. Makes sense 25 years later with cloud computer, when the cloud has replaced users local hard drives, and people use 3rd-party servers for longterm storage of their data, right? Didn’t think so. The good news is, this has been challenged legally, and at least one district court has called the SCA unconstitutional in Warshak v United States. The bad news is, the SCA isn’t the only relevant law at stake…
How the government can do whatever it wants
Enter the PATRIOT Act, a new government doctrine which says, in summary, that government can, with regards to getting information, basically do whatever it wants, whenever it wants, regardless of where the the information is stored. That means anything on any cloud is fair game for the government’s eyes. In fact, under the PATRIOT Act, somehow, the US government can get information off a server stored in Europe without a warrant or consent. Whoa. It’s already stopped one major defense firm in the UK, BAE, from adopting Microsoft’s Cloud 365 service, because they are afraid of the US government stealing state secrets off of the cloud, which is something that could happen under the PATRIOT act. Privacy being basically a notion of the past with this law, let’s move on to other legal issues.
Net Neutrality
The future of cloud computing is dependent on strong network neutrality laws that are not yet in place. If you are relying on the internet to provide functionality for you computer, and the internet becomes restricted, so does the functionality of your computer. For example, imagine that your ISP begins to put out a web productivity suite designed for use on the cloud. Should they choose to prioritize or filter data away from competitors on your Chromebook, not only does your ISP limit what you can do on the internet, they are now limiting the basic functionality of your computer. The idea that you are free to hack a device that you own to make it do whatever you want doesn’t really apply when the functionality of your product requires the ongoing participation of your ISP.
Jurisdiction
As we know, jurisdiction already makes things legally thorny on the internet. At any given time, you could be accessing data owned Australians hosted on Russian servers from your laptop in America, and it wouldn’t be uncommon. Right now, however, if an French website gets taken down for violating French laws, it might be upsetting to you if you like to visit that website. However, if your French cloud computing service, where you hold all of your data, gets taken down for violating French laws, it could mean the loss of all of your data. You may be bound by local laws with regards to what data you could be allowed to store on your cloud, effectively limiting what kind of data documents you can have. For instance, while in America the first amendment gives you every right to deny the Holocaust, you may not be able to store your papers saying so on cloud services in Germany. In fact, the a paper you had been writing, editing, and storing on a German cloud, could suddenly vanish, and you’d have no way of getting it back. Scary.
In summary…
The Internet is a complicated landscape legally. Cloud computing has many advantages, like making your data more portable, and allowing your computers to be more powerful. While Google would have you believe that using GoogleDocs is just like using Microsoft Word on your computer, and it may feel that way on the surface, legally the two are worlds apart.
...we really, really hope
In an interview two years ago, CEO Eric Schmidt was asked the question “People are treating Google like their most trusted friend. Should they be?”. His response? “If you have something that you don’t want anyone to know, maybe you shouldn’t be doing it in the first place.” Using cloud computing involves not only entering a complicated legal framework, but trusting your 3rd party cloud source, perhaps the way that Hoffa trusted Partin. For the time being, I don’t use GMail, and my programs, e-mail and data are on my personal hard drive. I don’t see that changing any time soon.














{kind=link}